このチュートリアルでは、BIツールのApache supersetを使ってデータセットの準備、編集、チャートの作成等のダッシュボードの作成の基本手順が学べます。
データセットの準備
ファイルのアップロード
まずはこちらのサンプルのcsvをダウンロードしましょう。
次にファイルをアップロードして、テーブルとして保存していきます。
Data > Databases をクリック。
デフォルトの設定では、「CSV upload」が使用不可のため変更します。
「Edit」から、ADVANCED > Security の「Allow data upload」にチェックを入れて、「CSV upload」を有効にします。

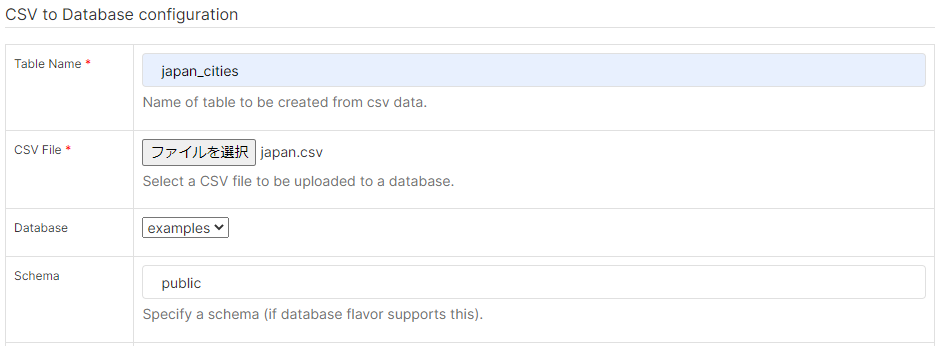
Upload file to database > Upload CSV から、Table Name, CSV File, Database Schemaを以下のように設定して「SAVE」します。(他項目に関してはデフォルトで問題ないです。)
テーブルが作成されたことがわかります。

※ Supersetの演習が完了後に、dockerコンテナ、イメージ、ボリュームを削除しましょう。ちなみに、docker system dfでdockerにより使用されているディスク総容量がわかります。
Databaseとの接続
ファイルをアップロードする方法の他に、データベースと接続してデータセットを作成する方法があります。
先程と同様にData > Databases をクリックした後、右上の +DATABASEボタンをクリックするとデータベースとの接続画面が出てきます。
フォームにhost名やport, DB名, Username, password等を入力するとデータベースと接続することが出来ます。
Data > Databasesをクリックした後、右上の +DATASETボタンをクリックするとデータセット作成画面が出てきます。
フォームからDatabase, Schema, table名を選択すると、データベースからデータセットを作成することが出来ます。
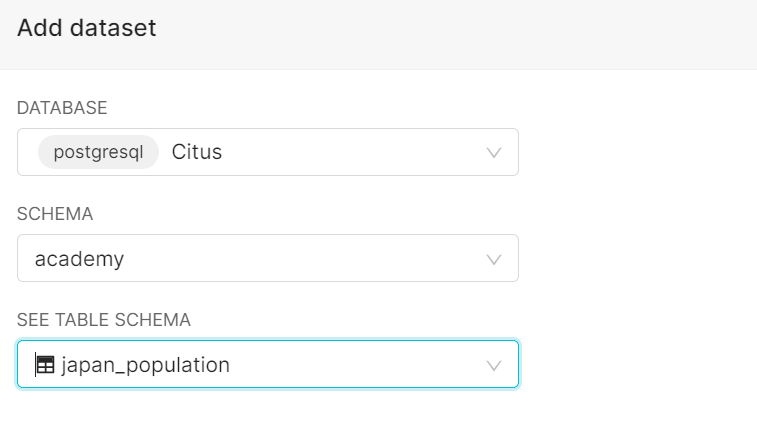
データセットの編集
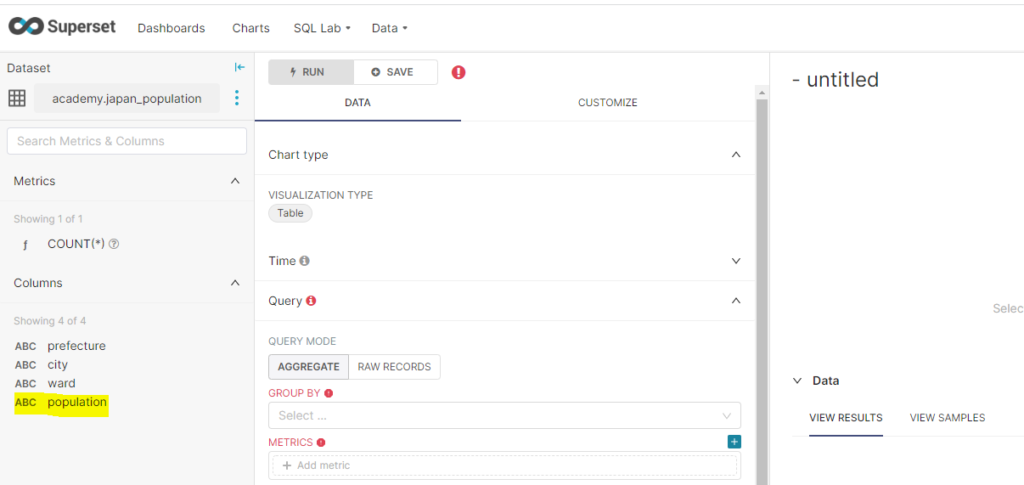
データセットの一覧画面から、先ほど作成したデータセットをクリックするとチャート作成画面に遷移します。
左側にデータセットのデータタイプとカラム名が表示されています。
数値型であるべきpopulatioのカラムがテキスト型になっていますのでチャート作成に移る前に、データセットを編集していきましょう。
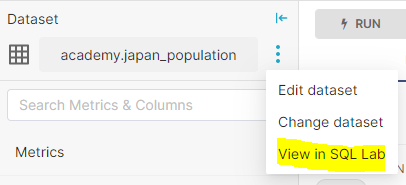
データセットのオプションボタンからView in SQL Labを選択するとSQl editor 画面が開きます。
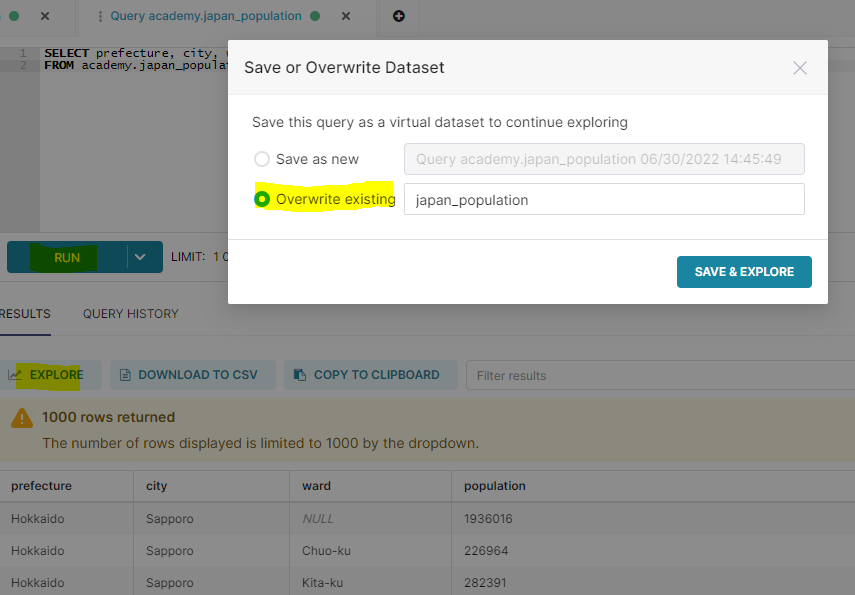
population カラムをinteger typeにキャストするSQLを定義し、RUNボタンで実行、EXPLOREボタンを押すとデータセットの保存画面が出てくるので今回はOverwriteします。
|
1 2 |
SELECT prefecture, city, ward, population::INTEGER FROM academy.japan_population |
チャートの作成1
まずは県別の総人口のチャートを作っていきます。
VISUALIZATION TYPE をクリックするとチャートのテンプレート選択画面が出てきます。
今回はBar Chartを選択します。
続いて、METRICSを編集していきます。
COLUMNはpopulation, AGGREGATEはSUMを選択します。また、タブ上部でLabel名の編集が出来ます。今回は”人口”としておきます。
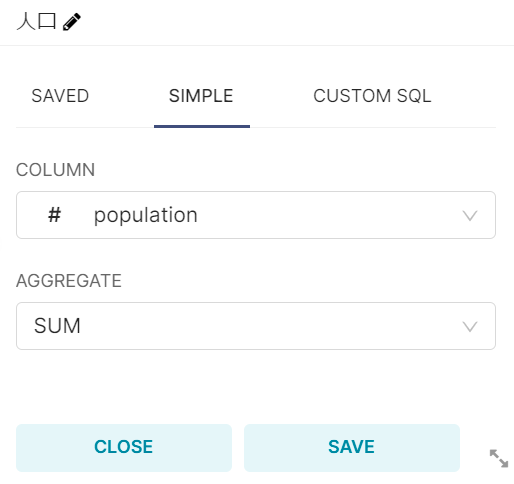
次にSERIESを設定していきます。SERIESとはSQLでいうところのGROUP BYの指定と同じです。
今回は県別の人口ですので、こちらにはprefectureカラムを定義します。
RUNボタンを押してQueryを走らせると下記のような Chartが表示されるはずです。
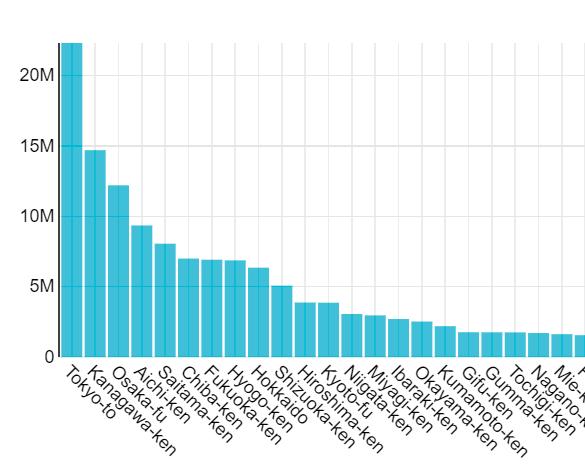
しかし、現時点では正しいデータが取れておりません。
問題点として、以下の札幌市のように、市(city)全体の人口と各区(ward)の人口が同じテーブル内にあるため、区を持つ都道府県の人口については、実際の人口よりも多くチャート上に表示されています。
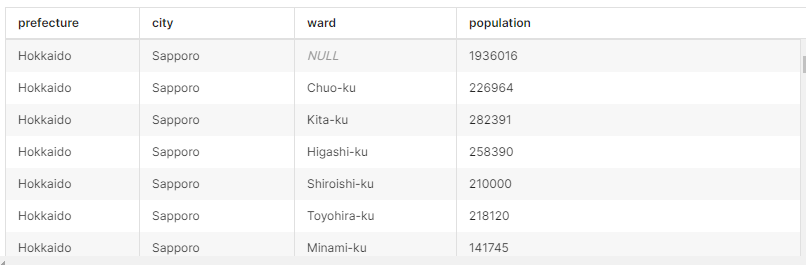
演習:この問題を解決するためのfilterを設定して正しい県ごとの人口を表すBar Chartを作成して下さい
完成したら画面上部のSAVEボタンから、チャートの名前を設定して保存します。
チャートの作成2
次に市ごとの人口を示すチャートを作っていきます。
VISUALIZATION TYPEからPivot tableを選択します。
metricsはカラムをpopulation, aggregateをMaxとします(市の値はユニークなので、MinでもSUMでも問題ないです。)
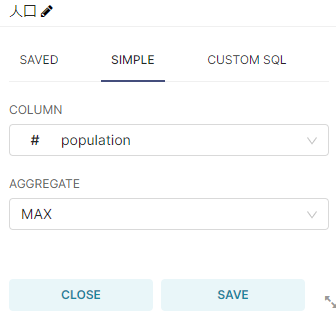
Group Byにはprefectureとcityカラムを指定します。
先程と同様の問題が生じるので、同じくFilterを設定しましょう。
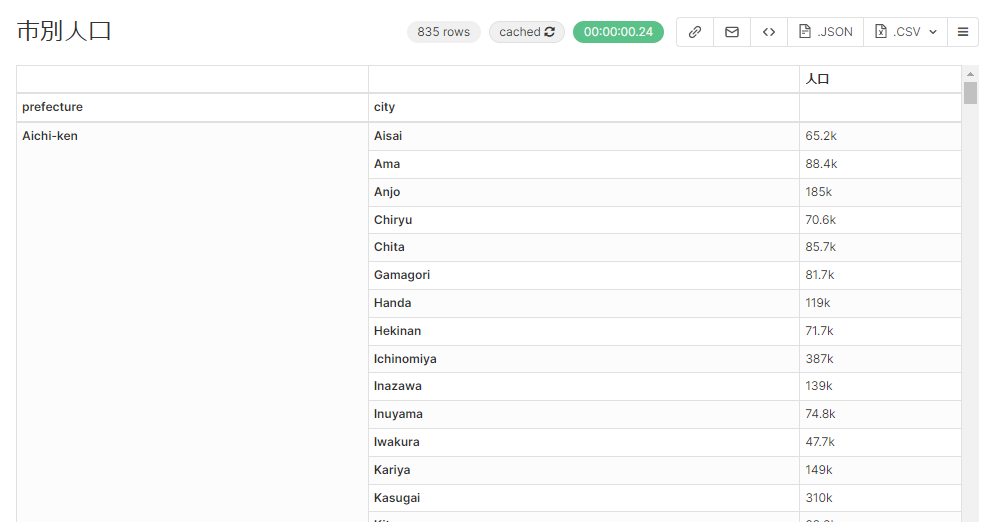
このようなtableが作成できていれば先程と同様にsaveしましょう。
ダッシュボードの作成
Dashboards > +DASHBOARDボタンを押し、ダッシュボード作成画面を開きます。
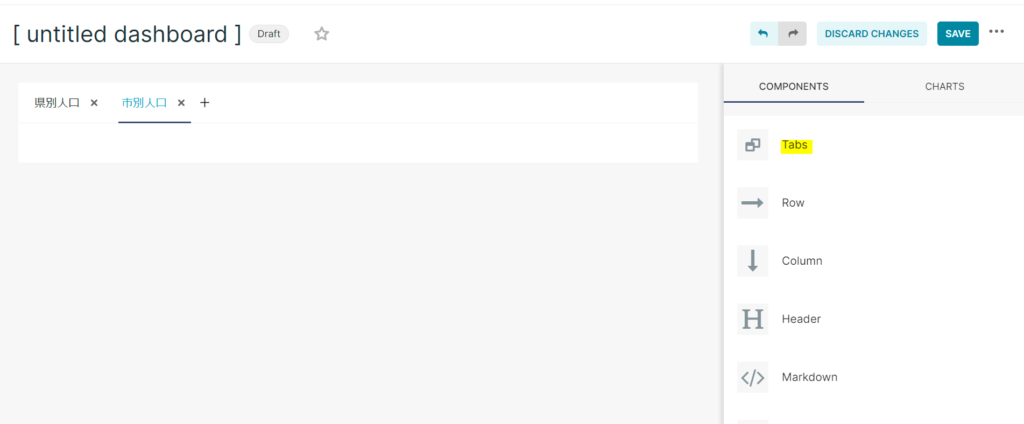
Dashboard作成画面の右側にあるtabから様々なComponentsをドラッグアンドドロップでダッシュボードへ追加することが出来ます。
下記のようにtabを追加してみましょう。
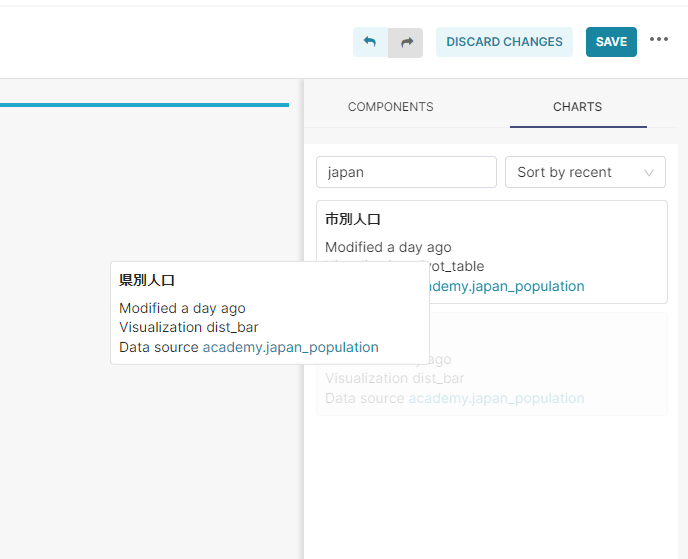
Charts tabからは作成済みのチャートを同じくドラッグアンドドロップで追加することが出来ます。
画面左のADD/EDIT FILTERS optionからはfilterを設定することが出来ます。
今回は県名のフィルターを定義しました
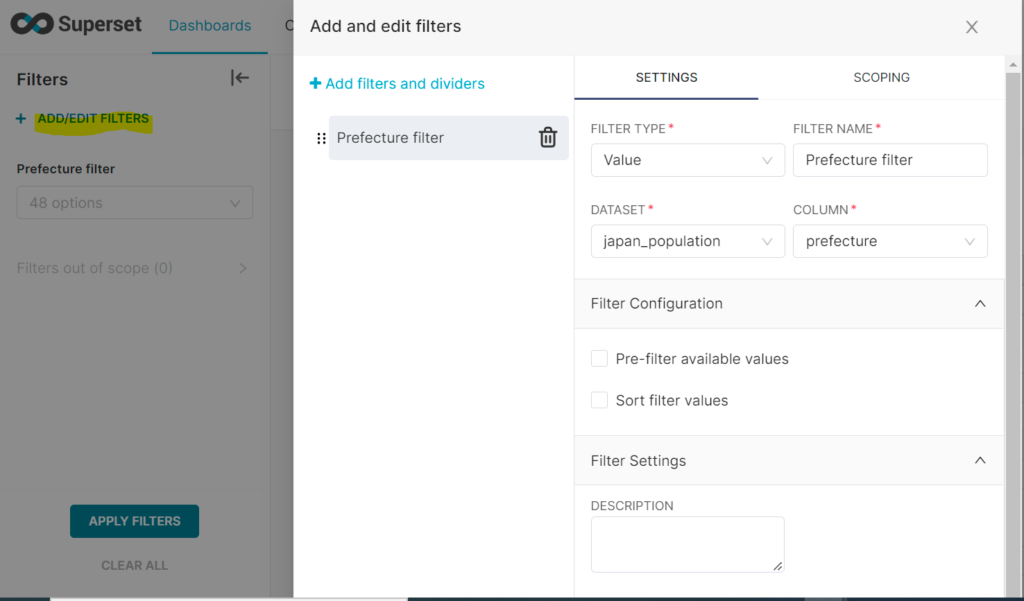
画面上部のタイトルを編集して、Saveすればダッシュボードの完成です。
今回紹介したもの以外にも様々なデータの視覚化をサポートする機能が搭載されていますので、公式ドキュメント等を参考に他の機能も試してみることがおすすめです。
あなたも、Avintonでこのような最先端技術を習得し活用してみませんか?
社員の成長を導きながら、AIやビッグデータなどの最先端技術をプロジェクトに活用していくことが私たちのビジョンです。Avintonの充実した技術研修でスキルアップを図り、あなたのキャリア目標を一緒に達成しませんか?

