![]()
機械学習入門者向け ChainerRLでブロック崩しの学習
- ルーティング
- データベースの命名規則
- 三目並べ – 2.〇×を交互にゲーム盤に入るようにしよう
- 三目並べ – 3.勝敗がつくようにしよう
- クリーンコード(Clean Code)
- 三目並べ – 4.「スタート」「リセット」ボタンをつけよう
- 三目並べ – 5.先攻後攻を決めて、コンピュータ対戦にしよう(前編)
- インフラストラクチャー(サーバー、コンポーネント、RAID)
- 機械学習入門者向け Support Vector Machine (SVM) に触れてみる
- YOLOv8を用いた物体検出
- 正規表現とパイプ
- 機械学習エンジニアに必要なスキル
- 軽量版Kubernetesディストリビューション – k0s クラスターの構築
- ファイル操作コマンド
- グループとユーザー
- 困った時に使うコマンド
- 一般グループのユーザーとグループ
- プライバシーポリシー
- 三目並べ – 6.先攻後攻を決めて、コンピュータ対戦にしよう(後編)
- フロントエンド開発のための環境構築
- ファイル検索コマンド
- 質問
- 仮想化環境のディスク容量を拡張する
- ユーザー権限とアクセス権
- データ分析基礎 – Part1
- 三目並べ – 0.導入
- テキスト処理
- データベースへのデータロード
- 機械学習概要1
- 機械学習入門者向け Naive Bayes(単純ベイズ)アルゴリズムに触れてみる
- ファイル管理
- SSHを使用してホストOSからゲストOSに接続する
- 機械学習入門者向け ChainerRLでブロック崩しの学習
- 機械学習入門者向け ランダムフォレストによる Kaggle Titanic生存者予測
- 機械学習概要2
- データ分析基礎 – Part 2
- 機械学習入門者向け 分類と回帰の違いをプログラムを書いて学ぼう
- フロントエンドのWeb開発について
- ダイナミックルーティング
- 三目並べ – 1.ゲーム盤を作ろう
- 【Python入門】Python Numpy チュートリアル
- Amazon EC2 インスタンスの初期設定をしよう
- AmazonEC2とVPCでネットワークとサーバーを構築しよう
- Apache NiFi Exercise
- Apache NiFi データパイプライン基礎
- Apache NiFiの環境設定
- Apache Spark 基礎
- Apache SparkとApache Zeppelinの概要と環境構築
- Apache Superset maptoolの使い方
- Apache Superset 基礎
- Apache Superset 概要と環境構築
- Apache Zeppelin 基本機能
- APIのデモンストレーション
- Avinton Academy コンテンツガイド
- AWS CLIをインストールしてコマンド操作しよう
- AWS CLIを使ってEC2のファイルをS3へアップロードしよう
- AWS Route 53を使って独自ドメインのWebページを表示させてみよう
- AWSアカウントの作成と必ずやるべきセキュリティ対策
- AWSのEC2インスタンスでWordPressブログを公開してみよう
- AWS入門者向け 初心者が最初に理解すべきEC2とVPCの基本的な用語解説
- CCNA
- Certbotを使ってSSL証明書を発行し、HTTP通信を暗号化しよう
- CISCO 1800ルータセットアップ
- CSV import & export – Node.js, mySQL – 1
- CSV import & export – Node.js, mySQL – 2
- Docker Compose(Nginx + Flask + MySQL)演習
- Docker Engineのubuntu上へのinstall
- Docker 概要とセットアップ
- Docker, Kubernetesの学び方について
- Dockerコンテナイメージの最適化/ベストプラクティス
- DockerとApacheを使ってWebサーバーを構築しよう
- EC2からS3へ自動でぽいぽいアップロードするスクリプトの作成
- ESP32-CAMのサンプルアプリケーションを実行する
- 01 – Sparkfun Inventor’s Kit の準備
- 02 – Sparkfun Inventor’s KitでLチカ
- 03 ポテンショメータでLEDの点滅間隔をアナログ入力する
- 04 フォトレジスタで明るさに反応するシステムをつくる
- 05 LCDに文字列を表示する
- 06 – BME280とLCDを組み合わせて温度計をつくる
- ESP32とArduino IDE/PlatfromIOでHello Worldアプリケーションの実行
- ESP32と超音波センサー HC-SR04 で物体の距離を計測する
- ESXi – Switchの追加とVLAN
- ESXi – VyOS
- ESXi – 小規模ネットワーク 構築
- Gitとは
- VS CodeでGitHub Copilotを設定する
- VSCode リモート開発環境
- GNS3のセットアップ
- Kubernetesクラスター上へのOpenVINOモデルサーバーを使用したサンプルアプリケーションのデプロイ
- Linuxとは
- NAT
- NodeJSでWebアプリケーション開発 – React編
- NodeJSでWebアプリケーション開発 – React編
- NodeJSでWebアプリケーション開発 – React編
- NodeJSでWebアプリケーション開発 – Socket.IO編
- NVIDIA Cumulus VX + GNS3でBGPネットワークのシミュレーション
- OpenCVのテストプログラム
- PacketTracerのセットアップ
- Pandasによる構造化データ分析
- PCからルータ、スイッチへのSSH接続設定
- PostGIS exercise
- PostgreSQL – Python – Apache – Bootstrap
- MySQLとMySQL Workbench のセットアップ
- PostgreSQL Setup
- PostgreSQL – インデックスを利用したパフォーマンス改善方法
- PostgreSQL – パーティショニングを利用したパフォーマンス改善方法
- PostgreSQLによるデータ分析
- postgreSQLへのshp fileのimport
- Python2.7とOpenCVのインストール
- Python3.8 と OpenCV のインストール (Ubuntu20.04LTS)
- Pythonでデータベースを操作する
- Pythonで画像を分類するプログラムを作成する
- Pythonによるマルチスレッドプログラミング実践
- Raspberry Pi 4B のセットアップ
- Raspberry PiとBME280を使用して温度と湿度、気圧を読み取る
- REDIS
- Redux基礎 – 主要な概念と用語
- Ruby on Rails を MySQLでセットアップ
- Ruby on Railsによる簡単なウェブアプリケーション
- SampleアプリケーションのKubernetes上へのデプロイ
- Scala 基礎
- scikit-learnとは
- Spark SQL エクササイズ
- SparkMLによるKaggle Titanic生存者予測
- KNIME, AutoMLライブラリによる住宅価格予測
- SparkMLによる住宅価格予測
- SQL 便利な関数
- Ubuntuの基本設定
- uhubctlでUSBデバイスのオンオフをコントロール
- Terraform入門 2 – Terraformのstate管理
- Terraform入門 1 – TerraformでAWS上にEC2インスタンスを作成する
- Virtualisation and Container (仮想化とコンテナ) – Ansible, Docker and Kubernetes
- viエディタ
- VLAN
- VMware ESXi サーバー構築
- Webアプリ開発に欠かせないGoogle Chrome DevToolsの基本
- Windows Server 2012 R2 Hyper-V
- Object Detection with YOLOv8
深層強化学習を用いたブロック崩しの学習
このアカデミーでは、深層強化学習向けライブラリのChainerRLを使用して、ブロック崩しの学習を体験します。この記事のコードは、chainerrlのquickstart.ipynb ChainerRL Quickstart Guideの一部を改変して作成しました。
扱うゲームを
- CartPore→Breakout
- Q関数で使用するネットワークの変更
- agentに過去4時刻分のゲーム画面を渡す
などの点を変更しました。
ChainerRLのインストールと環境構築
機械学習を用いた画像分類でインストールしたAnacondaが入っている前提で導入を進めます。
Anacondaインストール方法は 機械学習を用いた画像分類 で解説しています。
homeディレクトリに移動します。
|
1 |
$ cd ~ |
以降の環境導入に必要なパッケージのインストールをします。
|
1 2 3 |
$ sudo apt install git $ sudo apt install cmake $ sudo apt install zlib1g-dev |
今回使用するpythonのライブラリ(chainerとchainerrl)をインストールします。
|
1 2 |
$ sudo pip3 install chainer==2.1.0 $ sudo pip3 install chainerrl |
OpenAIGymの環境構築を行います。
|
1 2 3 4 |
$ git clone https://github.com/openai/gym $ cd gym $ pip3 install -e . $ pip3 install gym[atari] |
Jupyter notebookを使ってプログラムの実行
![]()
ここからは、実際にプログラムを実行していきます。
Anacondaをインストールしたときに入っている、Jupyter notebook形式での実行を推奨します。
こちらからBreakoutRetrain.zipをダウンロード してください。
上記のzipファイルをダウンロードしたら、ファイルを解凍し、
|
1 2 3 4 5 |
$ cd ~/Downloads $ unzip BreakoutRetrain.zip $ mv ~/Downloads/BreakoutRetrain ~/Documents $ cd ~/Documents/BreakoutRetrain $ jupyter notebook BreakoutRetrain.ipynb |
でダウンロードしたjupyter notebookを開きましょう。
以降はshift+Enterで各処理ごとのcellを実行していきましょう。
ここからは、プログラムの解説となります。
必要なライブラリのインポート
プログラムを実行するのに必要なライブラリをインポートします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import chainer import chainer.functions as F import chainer.links as L import chainerrl import gym import numpy as np from scipy import misc import matplotlib.pyplot as plt %matplotlib inline import time |
ゲーム環境の作成と確認
画像 : wikipedia
ゲーム環境の作成
ゲーム環境を作成し、OpenAIGymにおいてゲームの情報がどのように扱われているかを確認します。
まず、ブロック崩しのゲーム環境を作成します。また、ゲームの画面描画を4フレームごとに設定します。その後、ゲームから与えられる環境情報と、行動空間を確認します。
|
1 2 3 4 |
env = gym.make('Breakout-v0') env.frameskip = 4 print('observation space:', env.observation_space) print('action space:', env.action_space) |
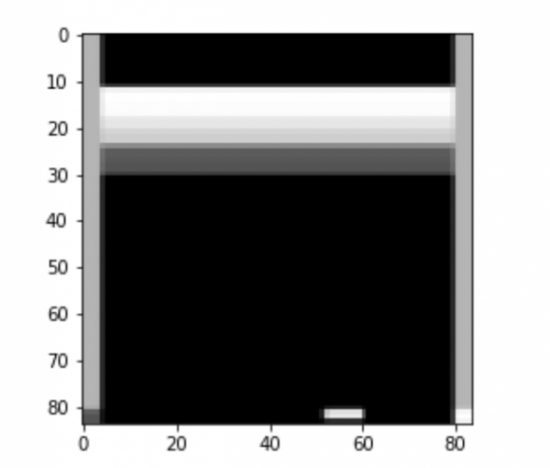
次に、ゲーム環境を初期化し、変数obsにゲーム画面の情報が代入されます。
このとき代入されたゲーム画面を84*84にリサイズするための処理を行います。
|
1 2 3 |
obs = env.reset() obs = obs[:,:,0] obs = (misc.imresize(obs, (110, 84)))[110-84-8:110-8,:] |
確認
リサイズされた画像の確認をします。
|
1 |
plt.imshow(obs, cmap='gray') |
ゲーム内での行動をランダムに選択し、中身を確認します(行動を表す数値が入っている)。
|
1 |
action = env.action_space.sample() |
実行
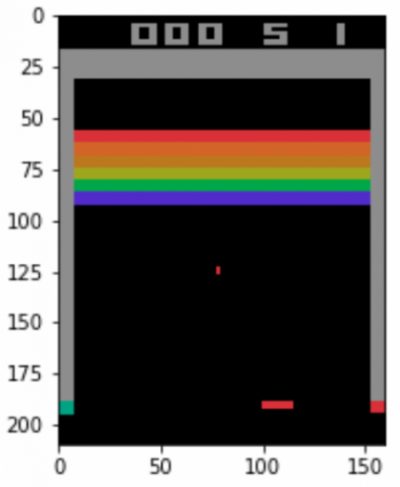
ゲーム内で行動を実行します。
その結果として行動後のゲーム画面( obs )、報酬値( r, 今回はブロックを崩すと+1 )、ゲームの終了判定( done, Trueで終了 )、学習には使用しない付加情報(info)が返ってきます。
|
1 2 3 4 5 6 |
obs, r, done, info = env.step(action) plt.figure() plt.imshow(obs) print('reward:', r) print('done:', done) print('info', info) |
Q関数の定義
Q関数の定義をします。今回は、84×84にリサイズしたゲーム画面×4時刻分を入力とし、出力にゲームでとることのできる行動を出力します。Q関数で使用するネットワークは、畳み込み層×3と全結合層×2から構成される畳み込みニューラルネットワーク(CNN)を用いています。各層の活性化関数にはReLU関数を採用しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class QFunction(chainer.Chain): def __init__(self, n_actions): super().__init__( L0=L.Convolution2D(4 , 32, ksize=8, stride=4), L1=L.Convolution2D(32, 64, ksize=4, stride=2), L2=L.Convolution2D(64, 64, ksize=3, stride=1), L3=L.Linear(3136, 512), L4=L.Linear(512, n_actions)) def __call__(self, x, test=False): h = F.relu(self.L0(x)) h = F.relu(self.L1(h)) h = F.relu(self.L2(h)) h = F.relu(self.L3(h)) return chainerrl.action_value.DiscreteActionValue(self.L4(h)) |
ブロック崩しにおいて取ることのできる行動の種類数を引数に渡して、Q関数を初期化します。
|
1 2 |
n_actions = env.action_space.n q_func = QFunction(n_actions) |
ネットワーク(Q関数)の最適化手法の選択
勾配の最適化手法にAdamを選択し、optimizerにQ関数をセットします。
|
1 2 |
optimizer = chainer.optimizers.Adam(eps=1e-2) optimizer.setup(q_func) |
各種パラメータの設定
学習用いる各種パラメータの設定を行います。ここでは学習率は0.95、探索手法はε-greedy法、過去の経験を参照するために保持しておくreplay_bufferのサイズを1000とします。また、np.float32形式ではないデータが発生したときにデータ形式を修正する関数を定義し、ここまでで定義した各種パラメータを引数で渡してDQNのエージェントを初期化します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
gamma = 0.95 explorer = chainerrl.explorers.ConstantEpsilonGreedy( epsilon=0.3, random_action_func=env.action_space.sample, ) replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 4) phi = lambda x: x.astype(np.float32, copy=False) agent = chainerrl.agents.DQN( q_func, optimizer, replay_buffer, gamma, explorer, replay_start_size=500, update_interval=1, target_update_interval=100, phi=phi) |
実際にゲームの学習を行う
ここからは実際にゲームの学習を行います。
実行時間の関係で、今回は事前に180ゲーム学習した状態から学習を再開します。
- n_episodesで学習するゲーム数を設定します。
- forループの中で実際に学習を実行します。
- forループの中では1ゲームごとにゲーム環境や報酬の合計値などを初期化しています。
- whileループの中では、1ゲームが終了するまでの間(今回はブロック崩しのボールを5個失うまで)、過去4時刻分のリサイズしたゲーム画面と報酬値をもとにゲームの学習を行います。
- 1ゲーム終了するごとに、現在のゲーム数とそのゲーム内での報酬値の合計(崩したブロックの総数)、学習にかかった累計時間を出力します。学習には約30分前後かかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
agent.load('Breakout180') n_episodes = 20 start = time.time() for i in range(181, n_episodes + 181): obs4steps = np.zeros((4,84,84), dtype=np.float32) obs = env.reset() obs = obs[:,:,0] obs = (misc.imresize(obs, (110, 84)))[110-84-8:110-8,:] obs4steps[0] = obs reward = 0 done = False R = 0 t = 0 while not done: action = agent.act_and_train(obs4steps, reward) obs, reward, done, _ = env.step(action) obs = obs[:,:,0] obs = (misc.imresize(obs, (110, 84)))[110-84-8:110-8,:] obs4steps = np.roll(obs4steps, 1, axis=0) obs4steps[0] = obs R += reward t += 1 print('episode:', i, 'R:', R) print('time:', time.time() - start) agent.stop_episode_and_train(obs4steps, reward, done) print('Finished') |
学習結果の保存
先ほど学習した結果に名前を付けて保存します。
|
1 |
agent.save(‘Breakout200’) |
学習結果の読み出しと確認
最後に学習ゲーム数が50、180、200の性能を比べてみましょう。
ゲーム数50のスコア平均
各ゲームごとの報酬値の合計を保持するための変数を用意します。
学習前のモデルを読み込み、実際に50ゲームテストプレイをします。
プログラムの流れはほとんど学習の時と同じですが、
この学習段階では、ボールを降らせる為の操作(action=1)を学習できていない状態に遷移すると、テストプレイ時に固まってしまうので、それを回避するためのコードが追加してあります。
また、#を消してenv.render()のコメントアウトを外すと、ゲームの様子が別ウインドウで開き確認することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
score50 = [0 for i in range(50)] agent.load('Breakout50') for i in range(50): obs4steps = np.zeros((4,84,84)) obs = env.reset() obs = obs[:,:,0] obs = (misc.imresize(obs, (110,84)))[110-84-8:110-8, :] obs4steps[0] = obs done = False R = 0 t = 0 while not done: #env.render() action = agent.act(obs4steps) obs, r, done, _ = env.step(action) obs = obs[:,:,0] obs = (misc.imresize(obs, (110,84)))[110-84-8:110-8, :] obs4steps = np.roll(obs4steps, 1, axis=0) obs4steps[0] = obs R += r t += 1 if np.allclose(obs4steps[0], obs4steps[3]): env.step(1) score50[i] = R print('test episode:', i, 'R:', R) |
最後に、スコアの平均値を表示します。
|
1 |
print(np.mean(score50)) |
ゲーム数180,200のスコア平均
先ほどののソースコードとほぼ同じなので載せませんが、Jupyter notebookにて実行してみてください。ゲーム数50の段階よりは打ち返せていると思います。
180と200については、視覚的な動きとしての差は少ないかもしれませんが、各ゲームごとのスコア平均をとると改善されていることが確認できるはずです(学習の進み方はランダムなので100%ではないですが、20回の学習で改善されやすい学習済みモデルを用意しました)。
学習結果の動画
50ゲーム学習済み
180ゲーム学習済み
200ゲーム学習済み
あなたも、Avintonでこのような最先端技術を習得し活用してみませんか?
社員の成長を導きながら、AIやビッグデータなどの最先端技術をプロジェクトに活用していくことが私たちのビジョンです。Avintonの充実した技術研修でスキルアップを図り、あなたのキャリア目標を一緒に達成しませんか?
採用情報

Avinton SDGs
