 今回はベイズの定理という数学(確率論)の定理をもとにした、Naive Bayes アルゴリズムと呼ばれる教師あり学習アルゴリズムについて説明します。 これは分類タスク向けのアルゴリズムで、文書データに対してよい結果を出すことが知られています。 用意してある、Jupyter notebookをダウンロードして実際にコードを書きながら学習することができます。 今回は、下記にコード例も最後に載せてあるので、ぜひ自分の手で実行して理解を深めてみてください。
今回はベイズの定理という数学(確率論)の定理をもとにした、Naive Bayes アルゴリズムと呼ばれる教師あり学習アルゴリズムについて説明します。 これは分類タスク向けのアルゴリズムで、文書データに対してよい結果を出すことが知られています。 用意してある、Jupyter notebookをダウンロードして実際にコードを書きながら学習することができます。 今回は、下記にコード例も最後に載せてあるので、ぜひ自分の手で実行して理解を深めてみてください。
ベイズの定理とは
機械学習のタスクでは、データセットが与えられたときに、それをもとにした推定がいくつかある中で、どの推定が最もらしいかということがよく問題になります。
例えば分類タスクでは、そのデータ点(サンプル)がどれに分類されるのかというのが、ここでいう推定ということになります。
このような、どの推定が最もらしいか判断するときに使えるのが、ベイズの定理と呼ばれる定理です。
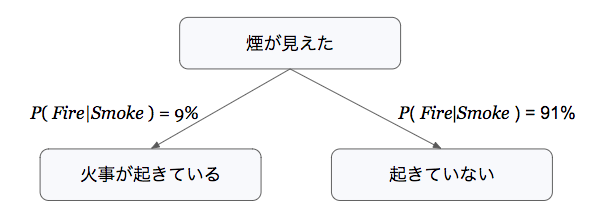
 実用例として、電車の混雑状況や、津波・地震などの災害予測、株価のリアルタイム予測などがあり、リアルタイムで状況を予測する機能です。
実用例として、電車の混雑状況や、津波・地震などの災害予測、株価のリアルタイム予測などがあり、リアルタイムで状況を予測する機能です。 テキスト分類とは、与えられた文書(Webページなど)をあらかじめ与えられたいくつかのカテゴリ(クラス)に自動分類することです。テキスト分類は、対象とするテキストによって幅広い応用ができます。例えば、すでに実用化されている機能としては、
テキスト分類とは、与えられた文書(Webページなど)をあらかじめ与えられたいくつかのカテゴリ(クラス)に自動分類することです。テキスト分類は、対象とするテキストによって幅広い応用ができます。例えば、すでに実用化されている機能としては、 センチメント分析とは、あるトピックに対して、その文章が肯定的であるか否定的であるか、あるいは中立的であるかを判断するものです。特定のテーマに対して、人々がどのように感じているかを分析する際に用いられます。
センチメント分析とは、あるトピックに対して、その文章が肯定的であるか否定的であるか、あるいは中立的であるかを判断するものです。特定のテーマに対して、人々がどのように感じているかを分析する際に用いられます。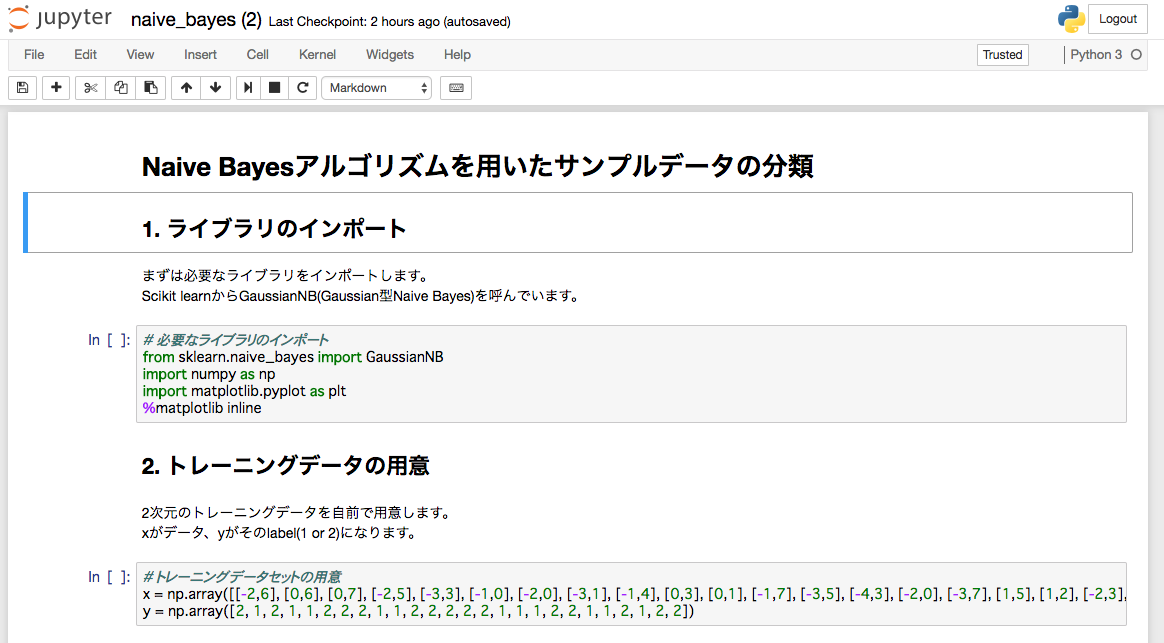 ここでは実際にScikit learnで実装したコード例を載せておきます。ぜひ実際に実行して、その手軽さを実感してみてください。 Naive Bayesの中には実はいくつかタイプがあるのですが、ここではGaussianモデルと呼ばれるものを用いています。 内容としては、自分で用意した2次元のトレーニングデータセットをもとに、新しい2次元データをlabel1かlabel2に分類するというシンプルなものです。 実際の実行は他の機械学習Academy同様、
ここでは実際にScikit learnで実装したコード例を載せておきます。ぜひ実際に実行して、その手軽さを実感してみてください。 Naive Bayesの中には実はいくつかタイプがあるのですが、ここではGaussianモデルと呼ばれるものを用いています。 内容としては、自分で用意した2次元のトレーニングデータセットをもとに、新しい2次元データをlabel1かlabel2に分類するというシンプルなものです。 実際の実行は他の機械学習Academy同様、
