scikit-learnはオープンソースのPython機械学習ライブラリです。
このライブラリには教師あり学習や教師なし学習に関するアルゴリズムが用意されているほか、
トイデータセットと呼ばれるサンプルデータセットが用意されているためすぐに機械学習を始めることができます。
scikit-learnで使えるアルゴリズム
回帰
過去の購買データや来場者数など連続する値に対して将来の値を予測することが可能です。
例えば、あるテーマパークの過去の来場者数の傾向をもとに向こう一週間の来場者数を算出することを単回帰分析、
過去の来場者数以外に天候や景気など複数の要因を追加して将来値を予測する重回帰分析などがあります。
分類
文字通り、あるデータがAに該当するかBに該当するか分類することです。
回帰と同様に予測などに役立つアルゴリズムですが、回帰がテーマパークに何人行くか数値を予測する一方、 分類はテーマパークに行きたいor行きたくないの二者択一を予測するアルゴリズムです。
クラスタリング
似ているデータごとにグループ分けすることです。 例えば、SNSに掲載している写真やコメントの傾向からクラスタリングを行い、同じグループに所属する人が 気に入ったものをレコメンドすることでSNSの利用満足度向上やSNS経由の商品購買率UPに繋がるでしょう。 分類と似た手法ですが、大きく異なるのは分類は正解データを学習することでグルーピングする「教師あり学習」である一方、 クラスタリングは正解データはなく単純にデータ間の類似度で分ける「教師なし学習」を採用している点です。
次元削減
元データの意味を保ったまま次元数を減らすアルゴリズムです。
例えば、あるクラスの幅跳びと走り高跳びの結果を跳躍力というデータとしてまとめることで二次元のデータを一次元にまとめることができます。
次元削減はデータ量が減るため計算コストの削減ができるほか、高次元ではできなかったデータの可視化が可能になる一方、データの具体性は元データに劣る点に注意が必要です。
アルゴリズムの選択
scikit-learnには、このように様々なアルゴリズムが用意されているため手軽に試すことができます。
また、下図にあるようにそれぞれの状況に応じてどのアルゴリズムを選択するべきかを示したチートシートと呼ばれるものが存在するため、 機械学習に関する深い知識を有していない人でも適切な手法を使うことができます。
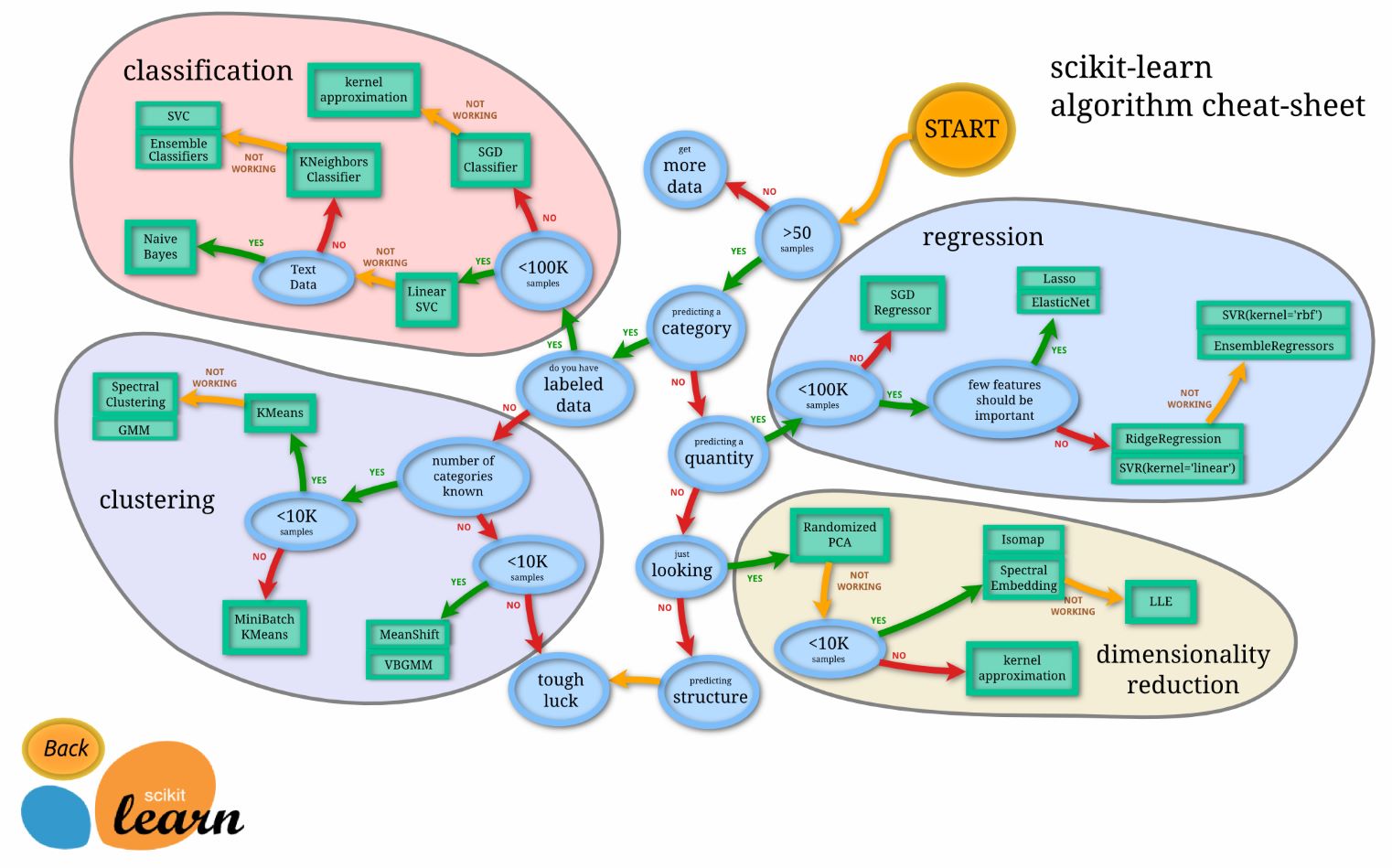 Choosing the right estimator – scikit-learn
Choosing the right estimator – scikit-learn
機械学習の流れ
1. データセットの準備
2. 学習用アルゴリズムを選定
3. 特徴量の選択・加工
4. モデルのトレーニング
5. 訓練済みモデルによる検証/評価
6. ハイパーパラメータの設定
scikit-learnチュートリアル
今回のチュートリアル及び演習はGoogle colaboratory上で行います。
まずは、新しいノートブックを作成します。
必要なライブラリをインポートします。
|
1 2 3 4 |
import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error |
サンプルデータを作成します。
|
1 2 3 4 |
# 特徴量(入力) X = np.array([[1], [2], [3], [4], [5]]) # ターゲット(出力) y = np.array([2, 4, 6, 8, 10]) |
先ほど作成したデータを学習用データ(train data)と検証用データ(test data)に分割します。
学習用データと検証用データは一般的に4:1程度の割合で分割します。
|
1 2 |
# データの分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
LinearRegression()で線形回帰モデルをインスタンス化します。
その後、fit()を使ってモデルをトレーニングデータに適合させます。
|
1 2 3 |
# 線形回帰モデルの構築と訓練 model = LinearRegression() model.fit(X_train, y_train) |
検証用データを使用して予測を行ったあと、最後に精度を確かめるためにMSE(mean squared error:平均二乗誤差)を算出します。
MSEは0に近いほど誤差が少ない(=精度が高い)と判断できます。
|
1 2 3 |
y_pred = model.predict(X_test) mse = mean_squared_error(y_test, y_pred) print("Mean Squared Error:", mse) |
演習
scikit-learnにはToy datasetと呼ばれる機械学習をすぐに始めてみたい人向けのデータセットが用意されています。
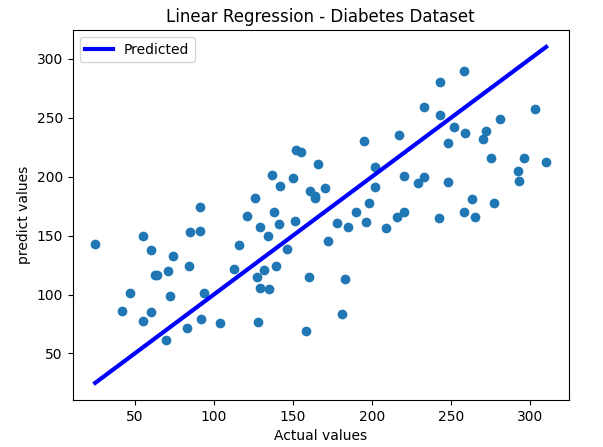
この演習では、diabetes dataset(糖尿病データセット)を使って年齢、性別、BMI、血糖値などの10個の特徴量から1年後の糖尿病の進行度(ターゲット)を予測する線形回帰モデルを構築します。
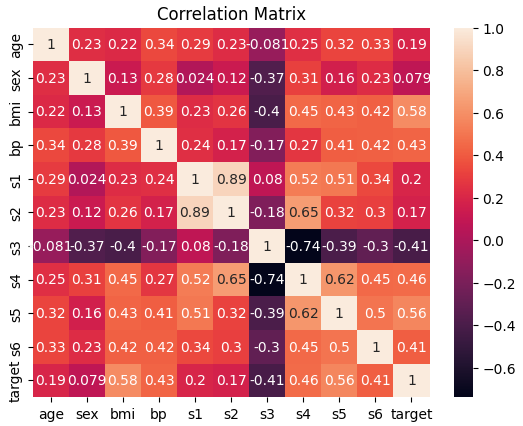
1. 各特徴量とターゲット(目的変数)の相関を下図のようなヒートマップとして可視化してみましょう
2. すべての特徴量をもとに一年後の糖尿病の進行度を予測します。
線形回帰モデルを構築して決定係数を算出し、予測値と実測値の関係を下図のようなチャートで表示しましょう