
Zeppelin notebook特有の基本的な機能を簡単な例を通して学ぶことができます。
準備
- Apache SparkとApache Zeppelinの概要と環境構築
- サンプルデータをダウンロード(男女別人口及び世帯数-行政区)
- curlコマンドを用いて以下2つのデータをダウンロードします。
-
-
- 男女別人口及び世帯数-行政区(令和4年3月)(CSV:2KB)yokohama2203.csv
- 男女別人口及び世帯数-行政区(令和4年2月)(CSV:2KB)yokohama2202.csv
-
-
- 2つのデータをユニオンし、保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
%spark val df2202 = spark .read .option("header","true") .csv("/data/yokohama2202.csv") val df2203 = spark .read .option("header","true") .csv("/data/yokohama2203.csv") val df = df2202 .union(df2203) df .write .mode("overwrite") .option("header", "true") .csv("/data/yokohama_2202_2203/") |
- cron schedulerを使用するための準備(Enable cron)
- zeppelin-site.xmlファイルを作成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>zeppelin.notebook.cron.enable</name> <value>true</value> <description>Notebook enable cron scheduler feature</description> </property> <property> <name>zeppelin.notebook.cron.folders</name> <value>/</value> <description>Notebook cron folders</description> </property> </configuration> |
-
- zeppelin-site.xmlファイルをdockerコンテナ内にコピー
|
1 |
docker container cp zeppelin-site.xml zeppelin:/opt/zeppelin/conf/zeppelin-site.xml |
-
- dockerコンテナのリスタート
|
1 |
docker restart <コンテナ名:zeppelin> |
環境
- Apache Zeppelin version 0.9.0
Zeppelin 基本機能
- input form
input formに2つのサンプルデータをユニオンして保存したディレクトリ名を入力してください。
|
1 2 3 |
%spark val directoryName = z.textbox("directory").toString |
- select form
select formで日付(2022-02-01 or 2022-03-01)を選択してください。
|
1 2 3 |
%spark val date = z.select("date", Seq(("2022-02-01", "2022-02-01"), ("2022-03-01", "2022-03-01"))).toString |
- checkbox form
checkbox formから適当な区を選択してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
%spark val options = Seq( ("鶴見区","鶴見区"), ("神奈川区","神奈川区"), ("中区","中区"), ("西区","西区"), ("南区","南区"), ("西区","西区"), ("港南区","港南区"), ("保土ケ谷区","保土ケ谷区"), ("旭区","旭区"), ("磯子区","磯子区"), ("金沢区","金沢区"), ("港北区","港北区"), ("緑区","緑区"), ("都筑区","都筑区"), ("戸塚区","戸塚区"), ("栄区","栄区"), ("泉区","泉区"), ("瀬谷区","瀬谷区") ) val ward = z.checkbox("ward", options).toList |
- show method
上記で設定した変数を使用して、以下のようにデータフレームを整形し、z.show()で表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
%spark val path = s"/data/$directoryName/" val df = spark .read .option("header","true") .csv(path) .filter(col("年月日")===date) .filter(col("市区名").isin(ward:_*)) z.show(df) |
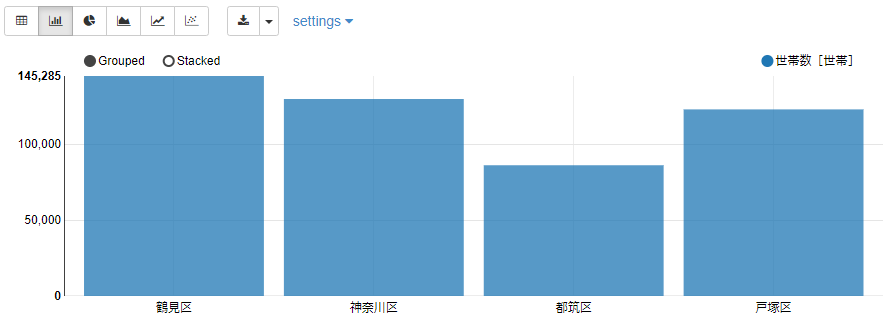
tableタブからtableを表示できます。

bar chartタブからbar chartを表示できます。
- cron scheduler
ノートブック上部のボタンから設定することができます。
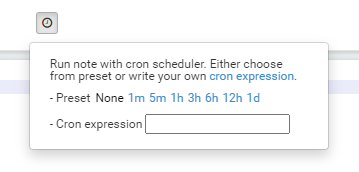
以下のcronジョブを設定してみてください。
- 1分ごとに実行
- 任意の時刻に実行(日本時間ではなく標準時であることに注意)
参考
あなたも、Avintonでこのような最先端技術を習得し活用してみませんか?
社員の成長を導きながら、AIやビッグデータなどの最先端技術をプロジェクトに活用していくことが私たちのビジョンです。Avintonの充実した技術研修でスキルアップを図り、あなたのキャリア目標を一緒に達成しませんか?

