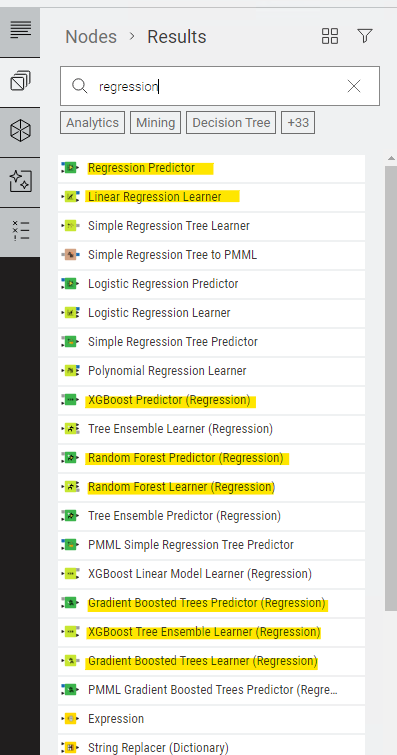
この項ではKaggle House Prices住宅価格予測をSparkMLというライブラリーを使って実施していきます。
タスクと表記のあるセクションは自分で調べながら実装して下さい。
KNIMEとは?
KNIME(ナイム)は、データの統合、前処理、分析、可視化、さらには機械学習までをノーコードで実行できるエンドツーエンドのデータ分析プラットフォームです。ワークフロー形式で直感的に操作できる点が特長で、デジタル人材や分析担当者が専門的なプログラミング知識なしで高度なデータ処理を行うことが可能です。
KNIMEはオープンソースかつ無償で提供されており、データの取得・変換から可視化、レポーティング、モデリングまで、データサイエンス全体のプロセスを一貫してサポートします。さらに、KNIMEではワークフローの構造が視覚的にわかりやすく、プロジェクトの再利用や他者との共有が容易であることから、チーム内のコラボレーションやナレッジの蓄積にも非常に適しています。