
このタスクでは、物体検出モデルYOLOv8を活用して、犬の検出を行います。
このコンテンツでは、無料で使えるアノテーションツールであるMake Sense AIとクラウド型のPython実行環境であるGoogle Colaboratoryを使用して取り組みます。
物体検出とは
物体検出とは、画像や動画の中から物体を検知する技術のことです。
物体検出は、画像や動画の中に特定の物体が確認された場合に位置や種類、個数を特定することができます。
製造業の外観検査、医療や建設業などに利用されることが多い技術で、身近な例では、スマホのカメラ、自動運転における歩行者の検知などにも利用されています。
YOLOとは
YOLO(You Only Look Once)とは処理速度が他のモデルより高速な物体検出アルゴリズムの1つです。
YOLOには様々なバージョンがあり、現在では、YOLOv1〜v11まであります。(2025年1月時点)
本コンテンツで使用するYOLOv8は、PyTorchを使用しており、処理速度、精度が高くバランスの良いモデルです。
※PyTorchは、Pythonのオープンソース機械学習ライブラリです。
データセット
データセットとは、AIや機械学習モデルを学習させるために用意された、まとまったデータの集まりです。
物体検出は、このデータセットを使用して検出する物体の特徴を学習させて行います。
1. データセット画像の取得
Dog_images.zip
こちらの100枚の犬の画像をダウンロード後、zipファイルを解凍します。
imagesフォルダとlabelsフォルダを作成し、ダウンロードした画像をimagesフォルダに格納してください。
データ取得元:Kaggle Animal Faces
※今回はKaggleからデータセットをダウンロードしています。
※検出したい物体を決めて、ネット等で集めた画像を使用しても構いません。
※Kaggleは、世界中のデータサイエンティストが集まって、データ分析や機械学習の課題に挑戦するプラットフォームです。

Make Sense AIを使用したアノテーション
物体検出を行う前に、画像内のどれが犬にであるのかをAIに学習をさせるために、ラベルを付ける必要があります。
この作業のことをアノテーションといいます。
今回はMake Sense AIという、ブラウザ上で動作するツールを用いてアノテーションを行います。
アノテーションの手順
1.以下のURLをクリックしてサイトにアクセスします
2.Get Startedをクリックします
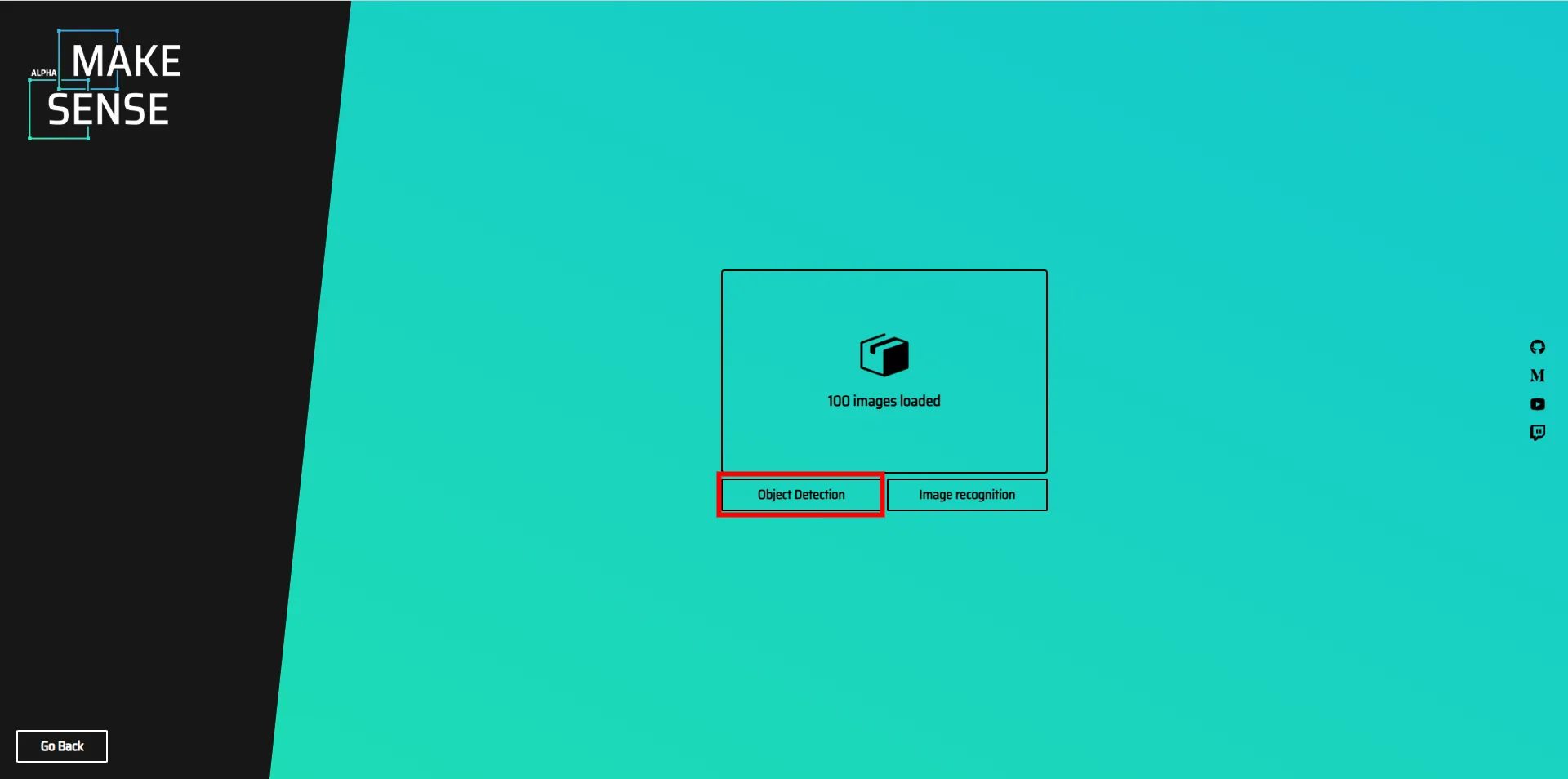
3.赤枠の部分をクリックし、先ほど取得したデータセットをインポートします

4.赤枠内のObjectDetectionをクリックします
5.赤枠内をクリックする
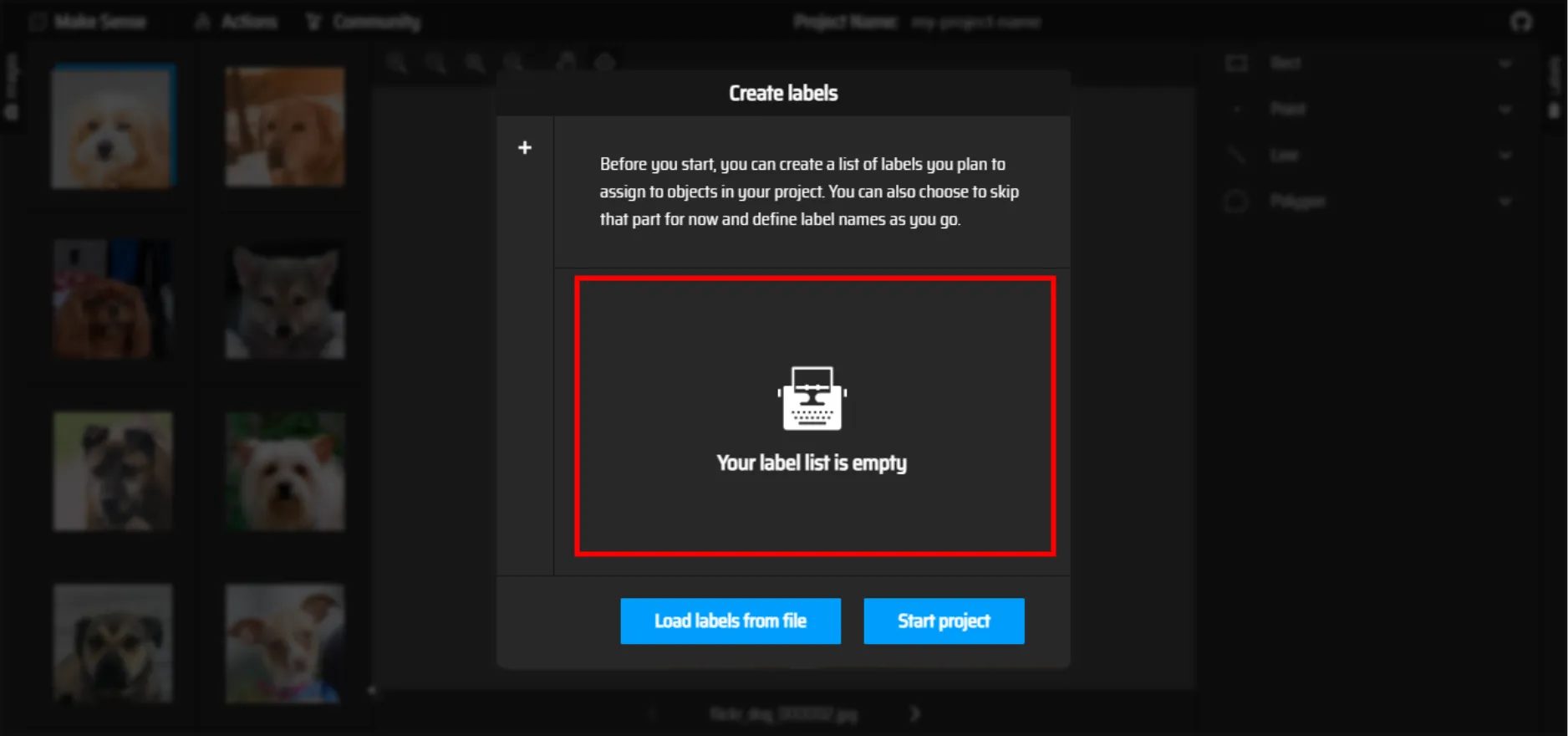
ラベルの名前を付けることができるので、dogと名前を付け、Start projectをクリックしてアノテーションを開始しましょう
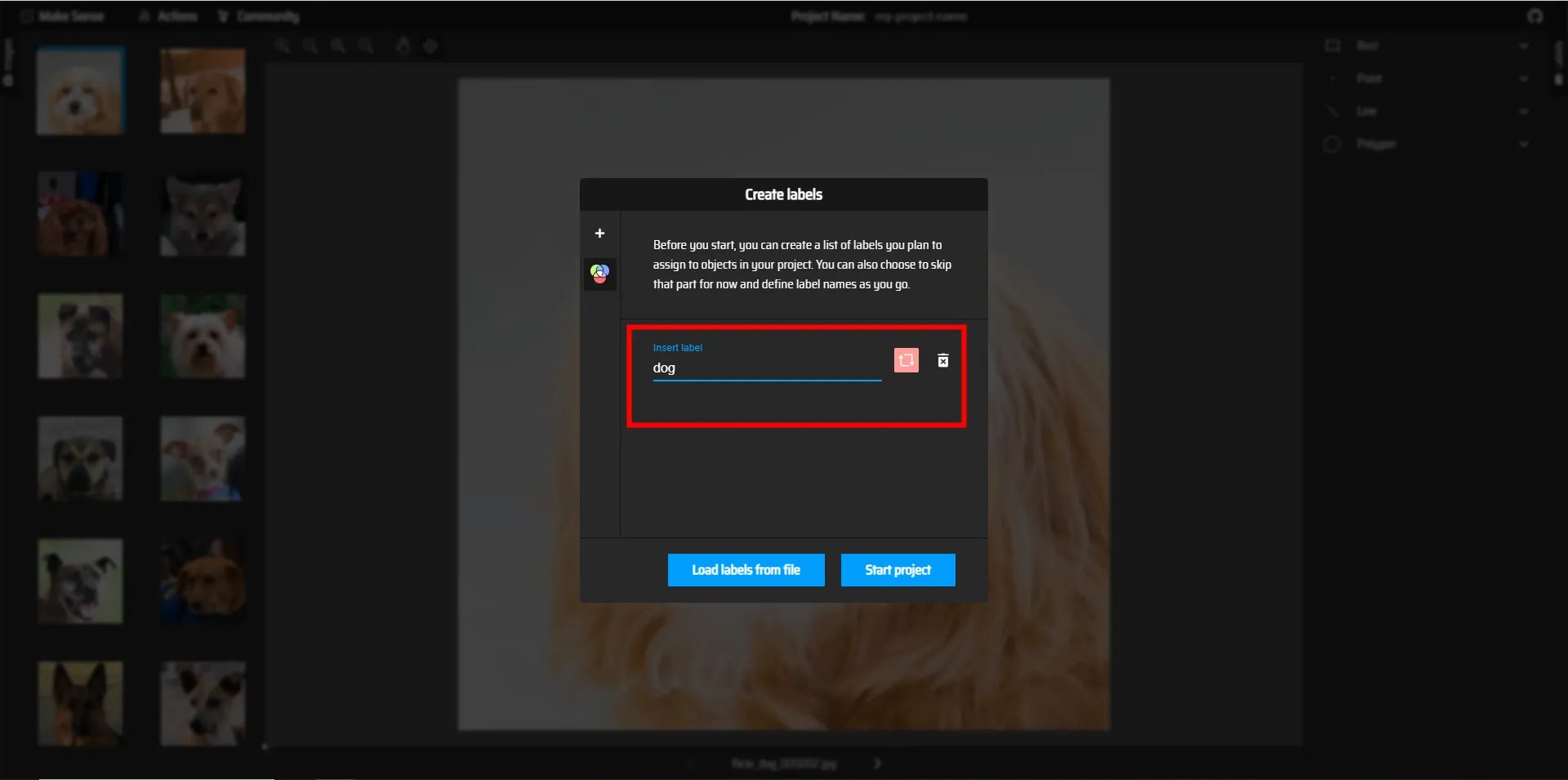
6.今回のアノテーションは矩形ラベルによる範囲の指定で行うため、Rectを選択します
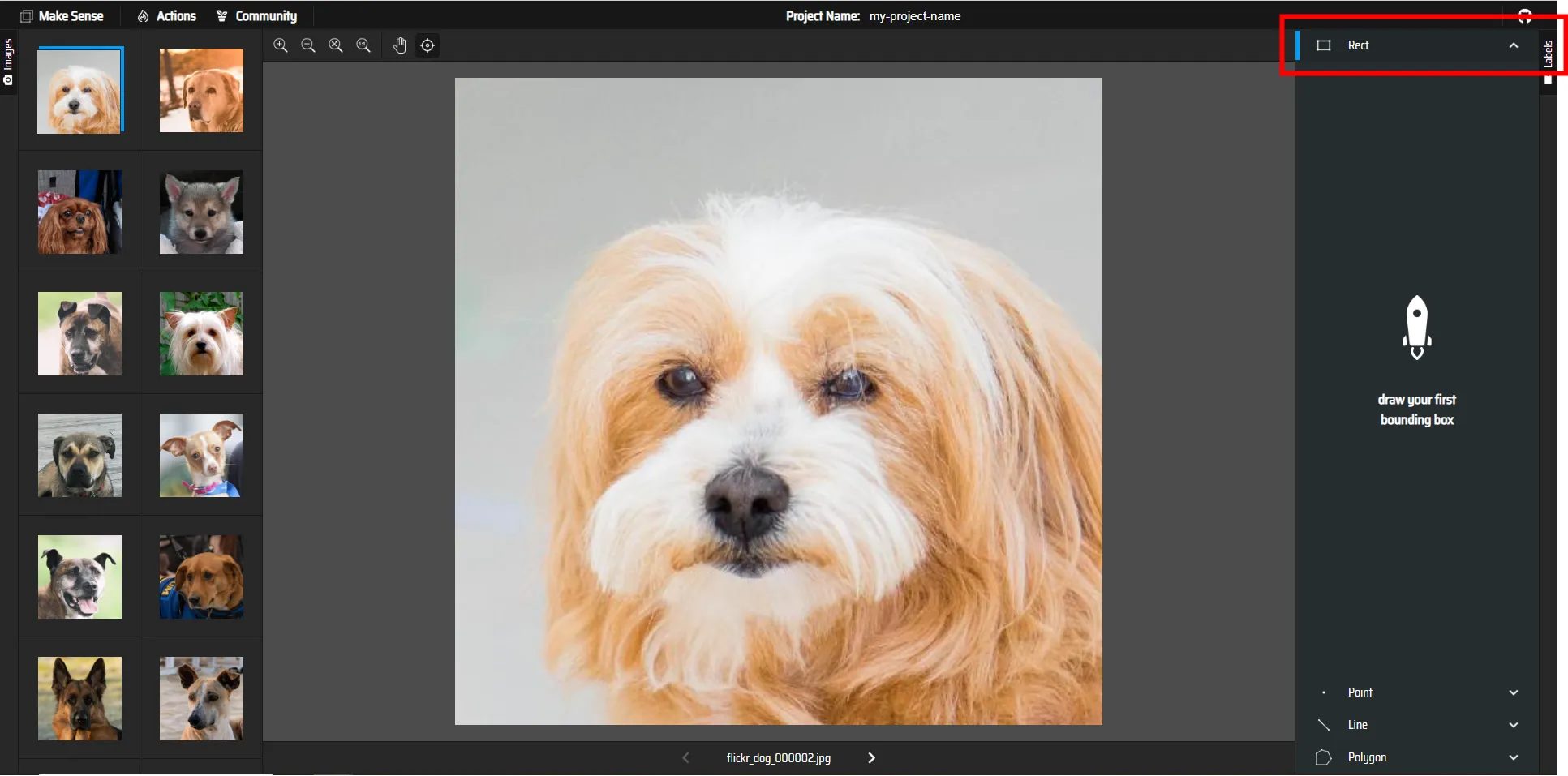
7.画像内の犬の範囲を選択します。
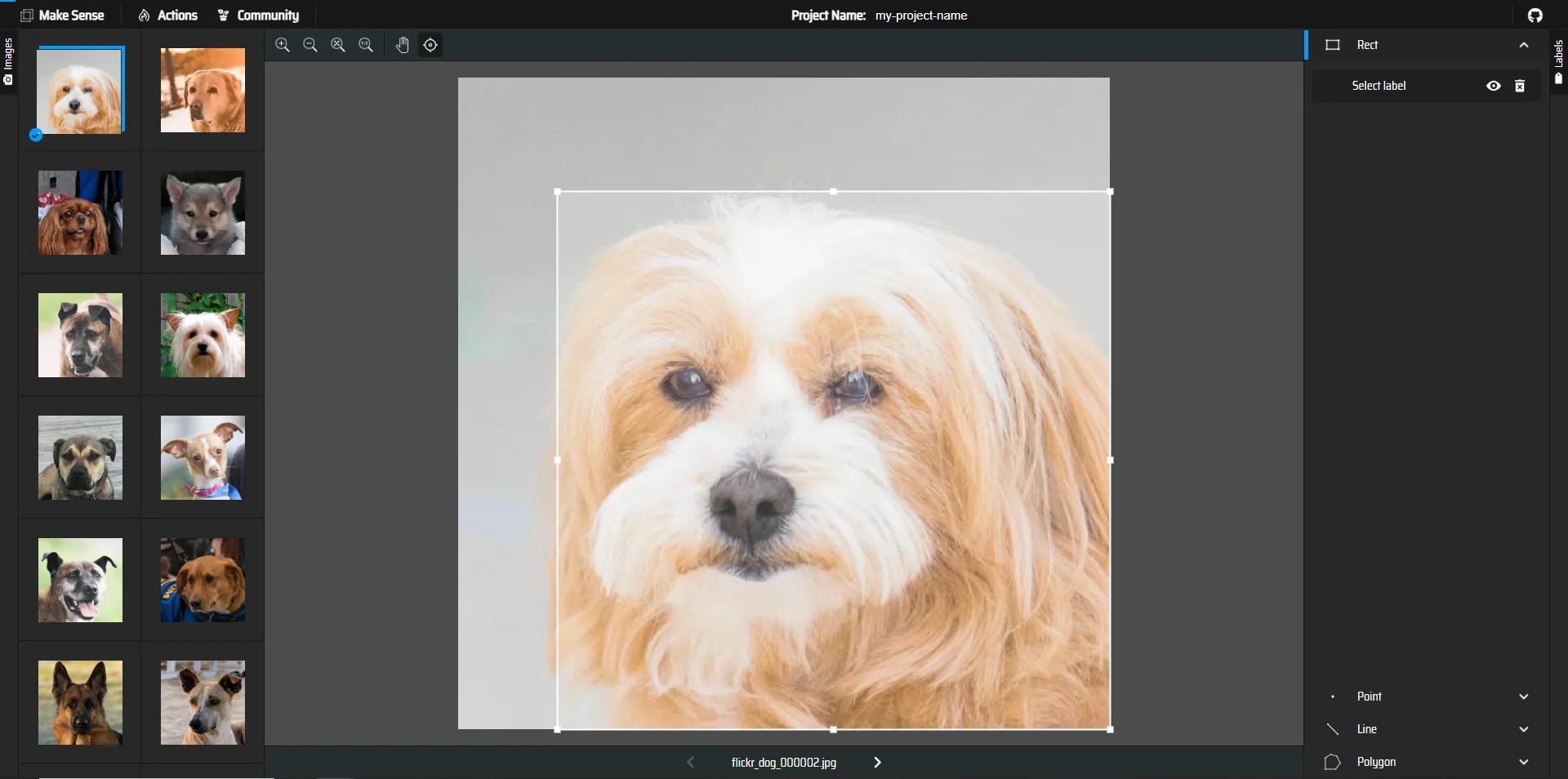
赤枠の箇所にSelect Labelと表示されるので先ほど作成したラベル、dogを選択します
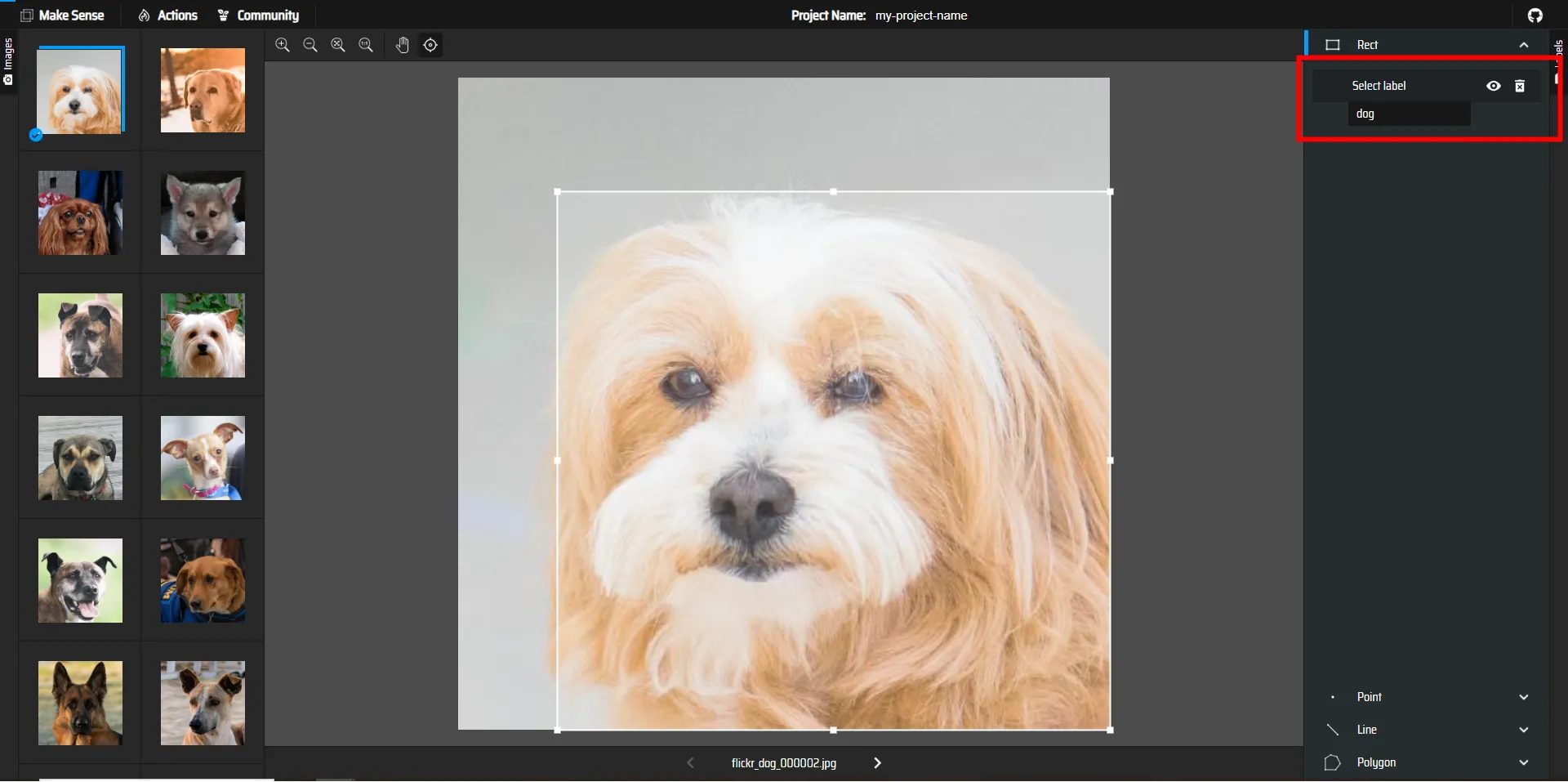
これで、この範囲が犬であるとラベルを付けることができました。
8.次の画像をクリックしてラべルを付けていきます。
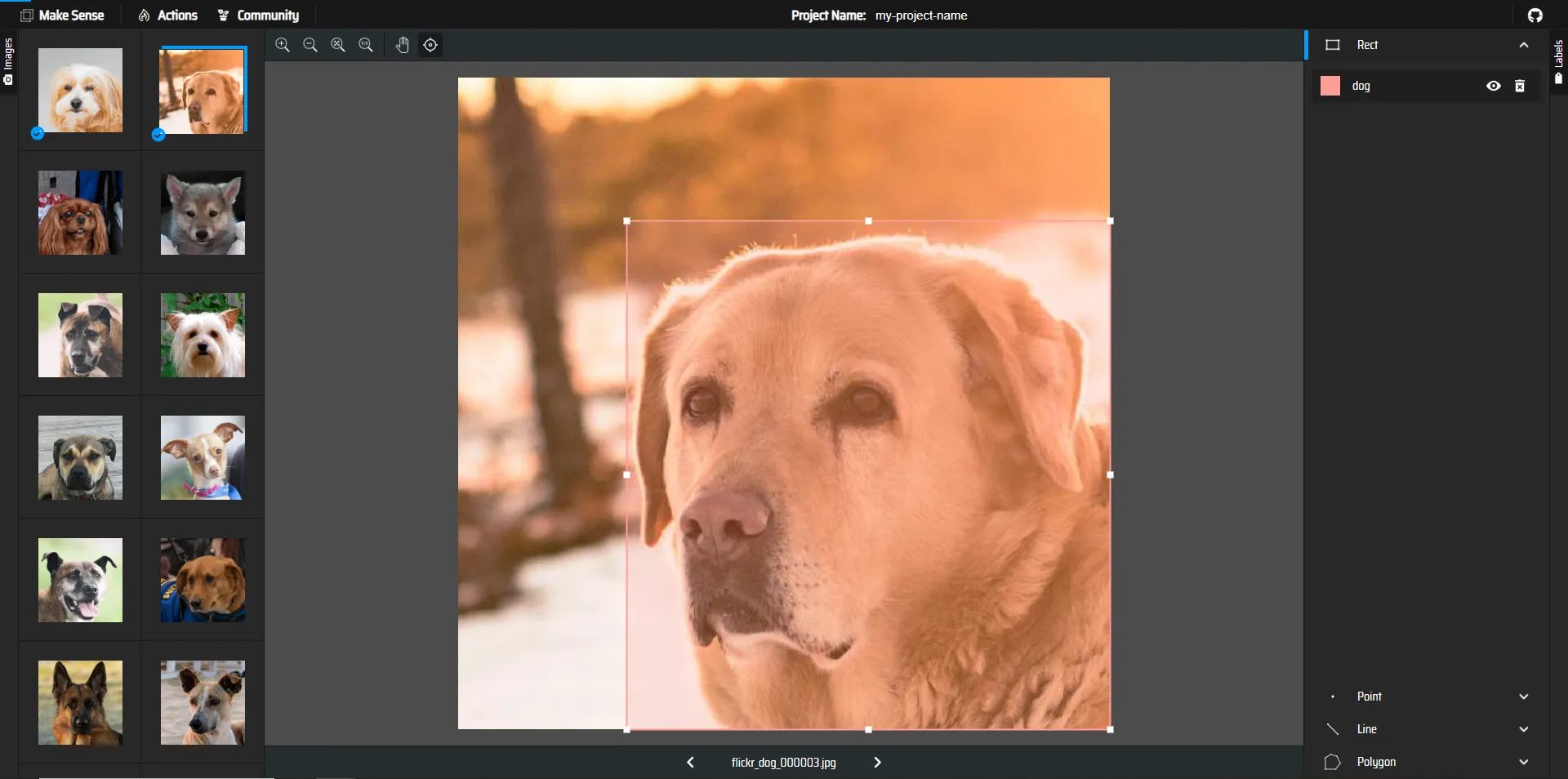
この要領ですべての画像のアノテーションを行っていきましょう。
注意
Make Sense AI はブラウザ上で動作するアプリケーションのため、作業は途中保存されません。
9.アノテーションが完了したら、左上のActionをクリックして
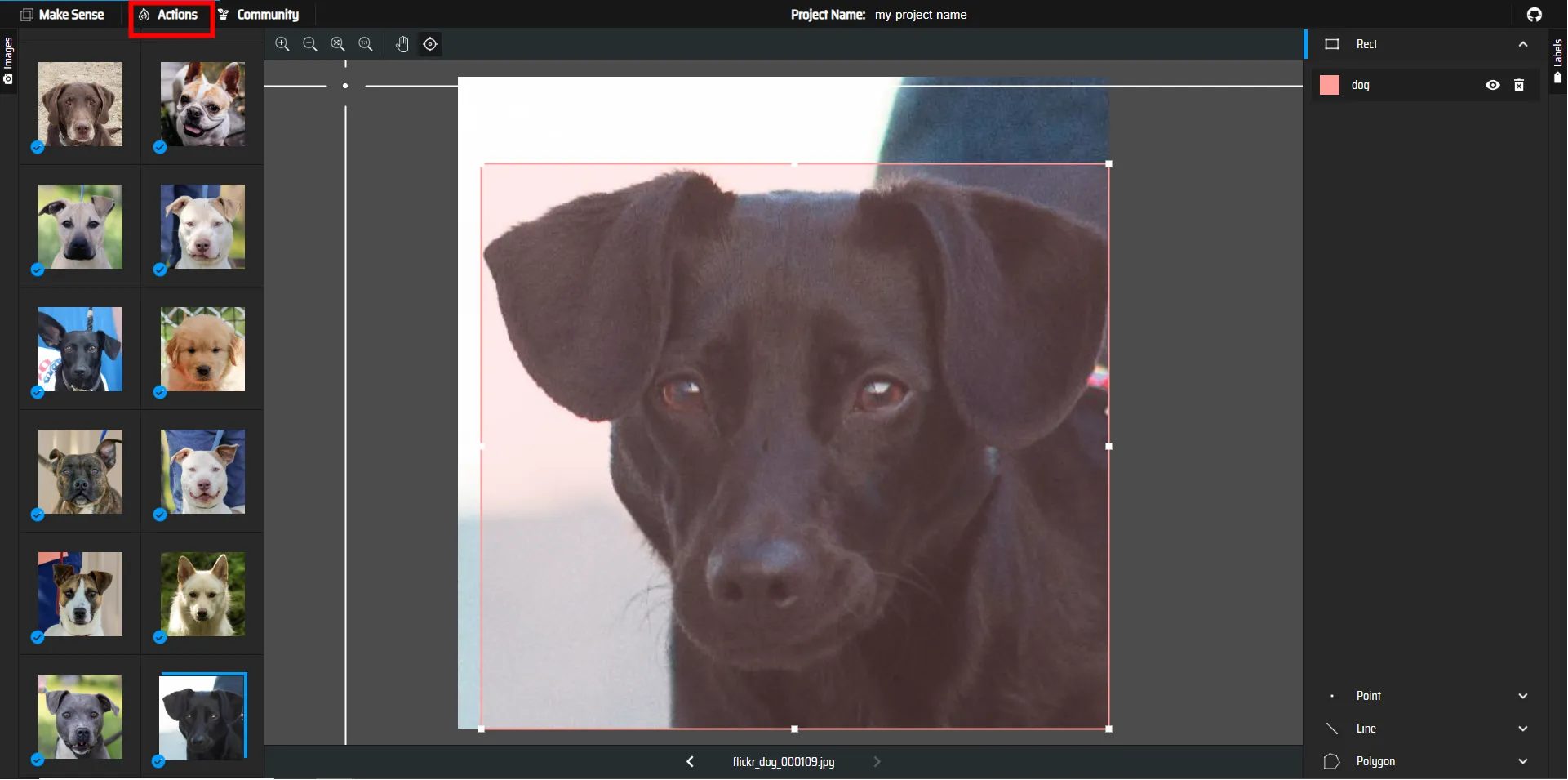
Export Annotationsを選択します
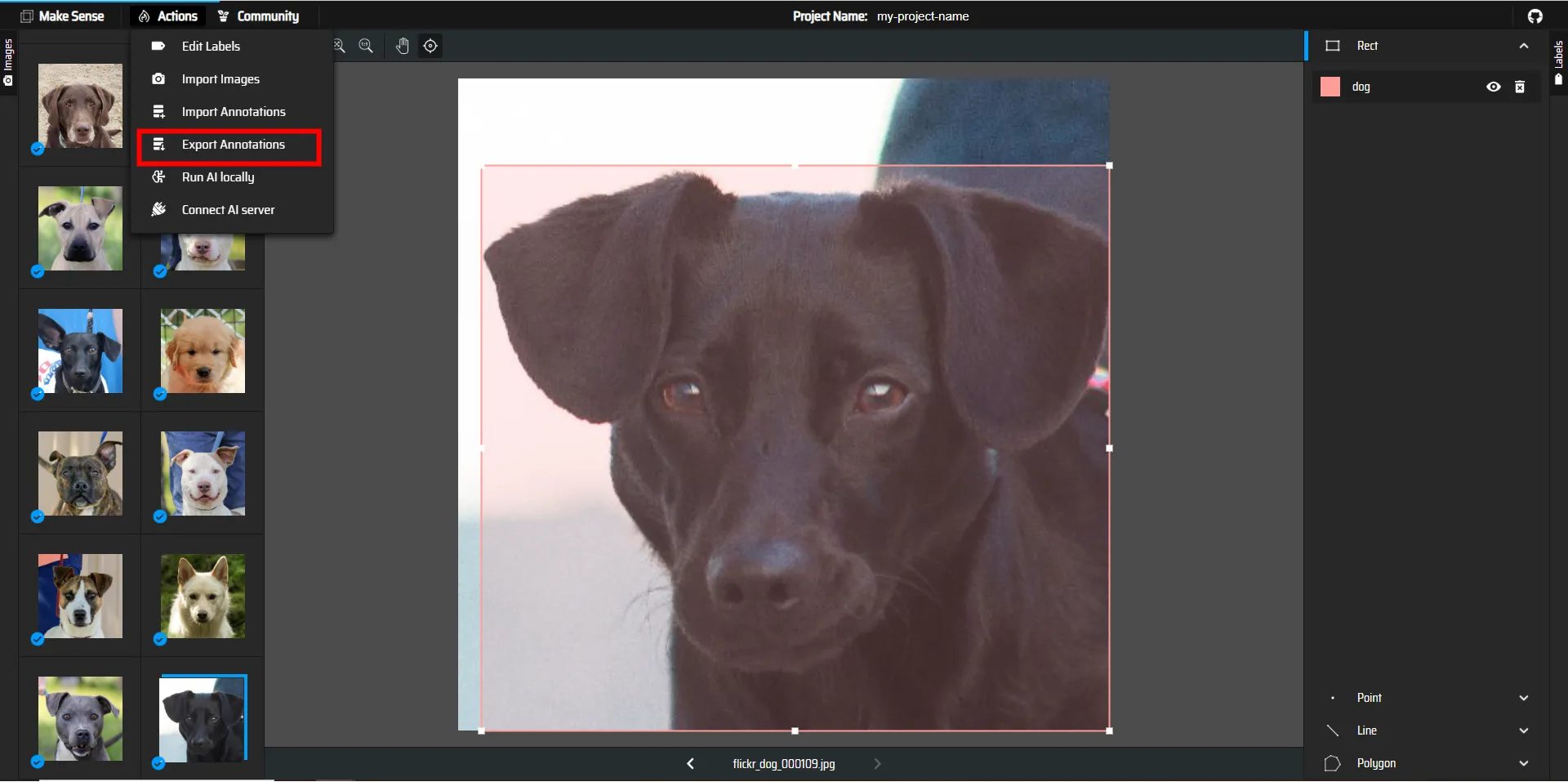
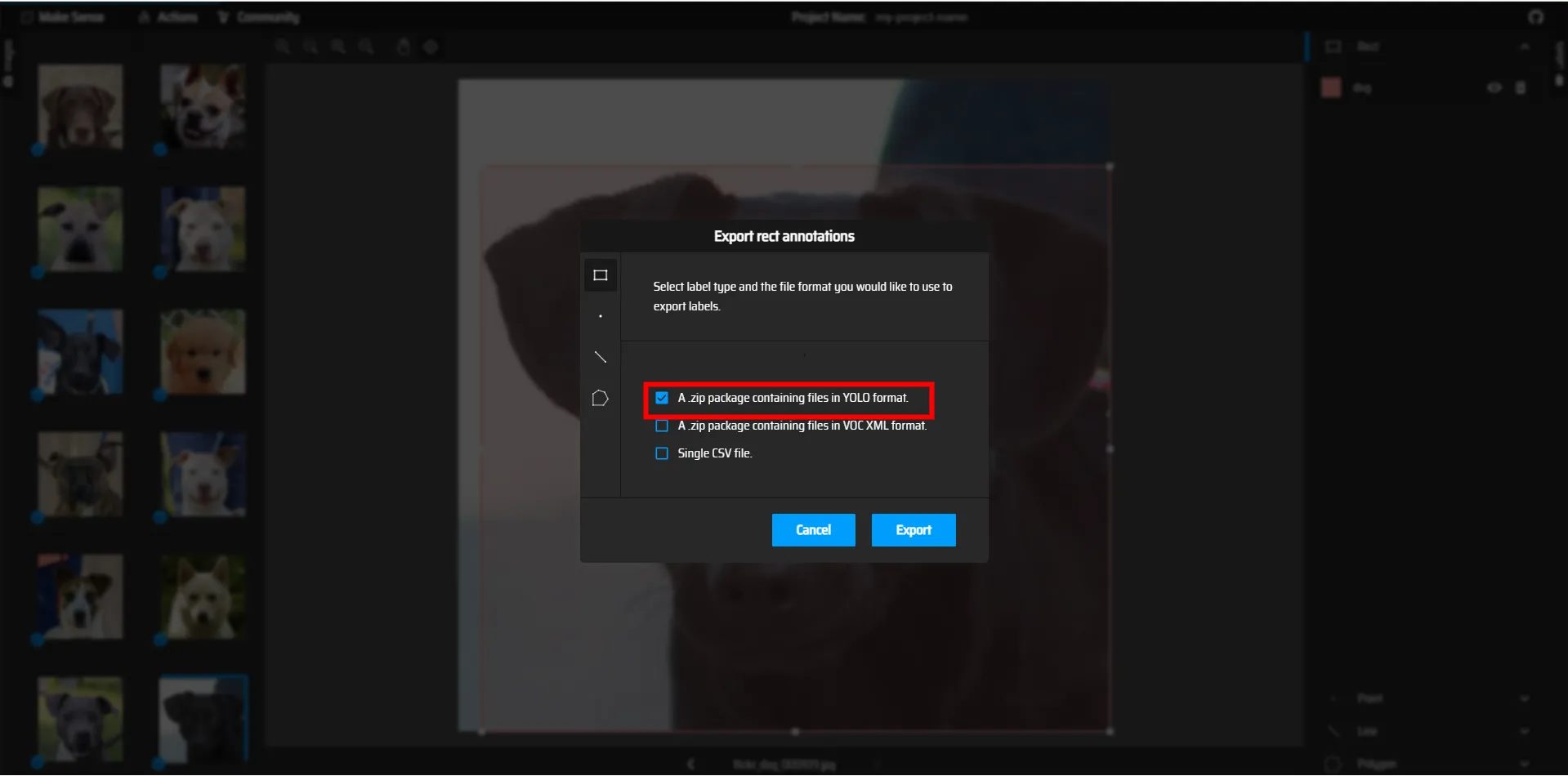
YOLO形式で保存するため一番上のチェックボックスにチェックを入れて保存して、保存されたファイルを解凍しましょう。
訓練データと検証データ
ラベル付けが終わったら、以下のようなディレクトリ構造でドライブ上に作成します。
学習に使用する画像ファイルと、先ほどラベル付けを行ってダウンロードしたファイルを訓練データ(train)と検証データ(valid)をペアとして以下のようなファイル構造でランダムに振り分けるプログラム(例 train : 8 , valid :2)を作成してください。
- Image(100枚) : train:80枚 valid:20枚
- label(100枚) : train:80枚 valid:20枚
Directory Structure
|
1 2 3 4 5 6 7 |
# dataset/ # ├── images/ # │ ├── train/ ← 学習用画像(.jpg/.png) # │ └── val/ ← 検証用画像 # └── labels/ # ├── train/ ← train に対応する .txt(YOLOフォーマット) # └── val/ ← val に対応する .txt |
YOLOv8を用いた学習
ここからは学習フェーズになります。
用意した訓練データを用いて、モデルに学習させましょう。
開発環境はローカルでも良いですが、GPUを使うためにGoogle Colaboratory を使用することにします。
GPUを使って学習することで以下のメリットがあります。
- 学習時間の短縮
- モデル改良の試行回数を増やせる
- 推論速度の向上
- リアルタイム検出アプリへの応用が容易
- 大規模データへの対応
- データ拡張や高解像度画像も快適
1.Google Driveの任意の場所に作業ディレクトリ(フォルダ)を作成
データセットや学習結果が保存されるディレクトリ(フォルダ)を作成します。
2.画像データをGoogle Driveにアップロード
Google Driveを開き、先程用意したデータセットを 1. で作成したディレクトリにアップロードしてください。
3.Google Colaboratoryを開きます。
1. で作成した作業ディレクトリに移動し、
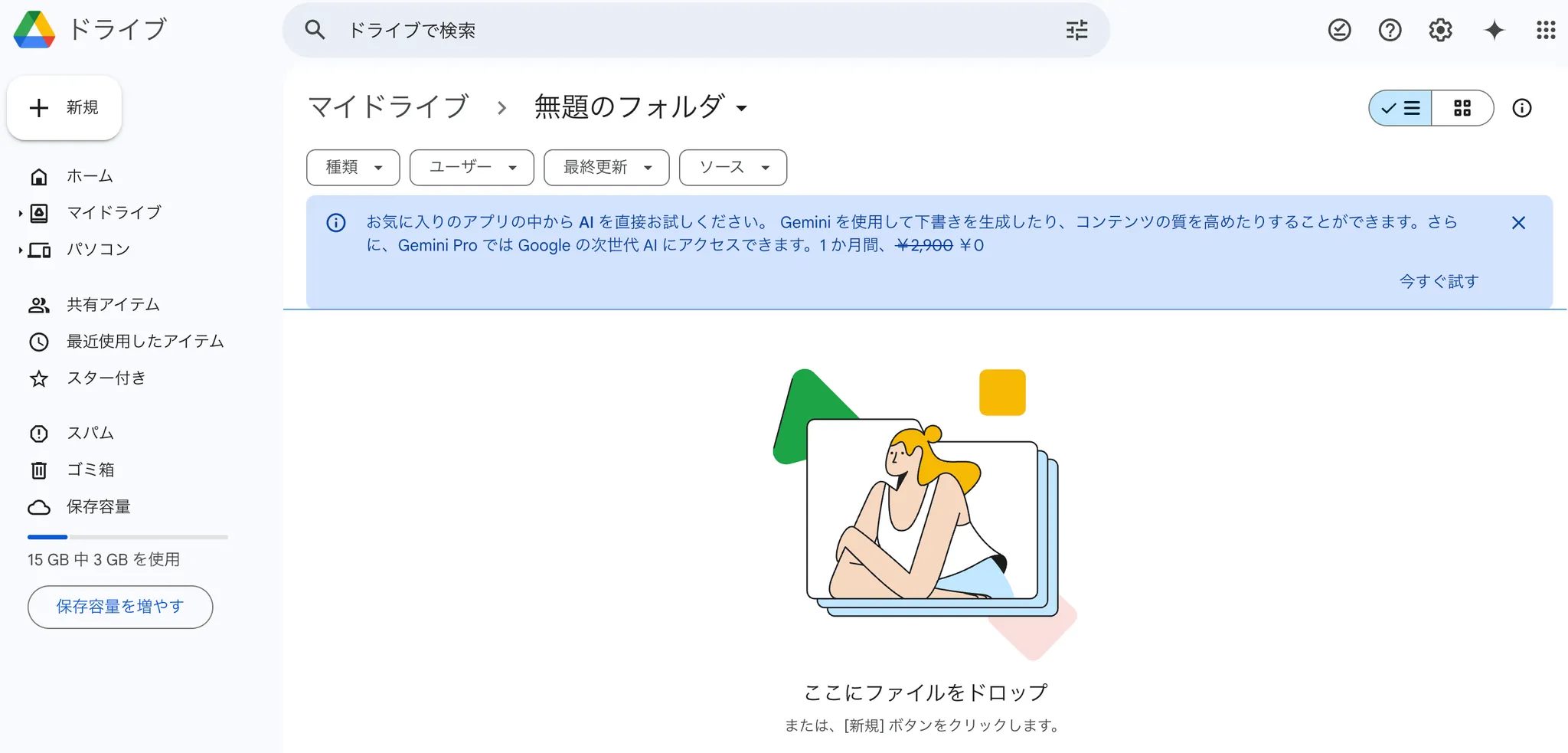
右クリックをした後に、「その他」を選択してください。
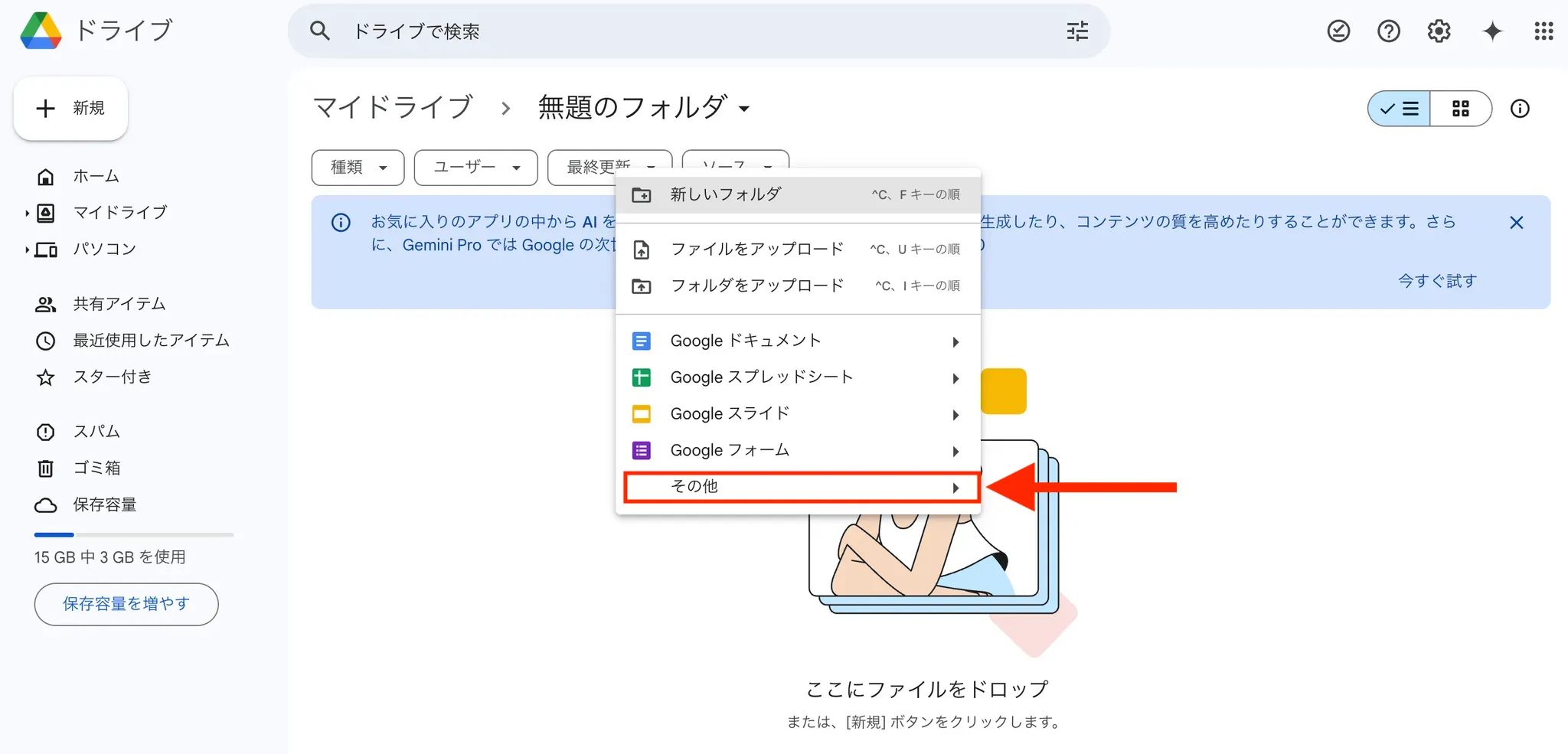
Google Colaboratoryを選択して開きましょう。
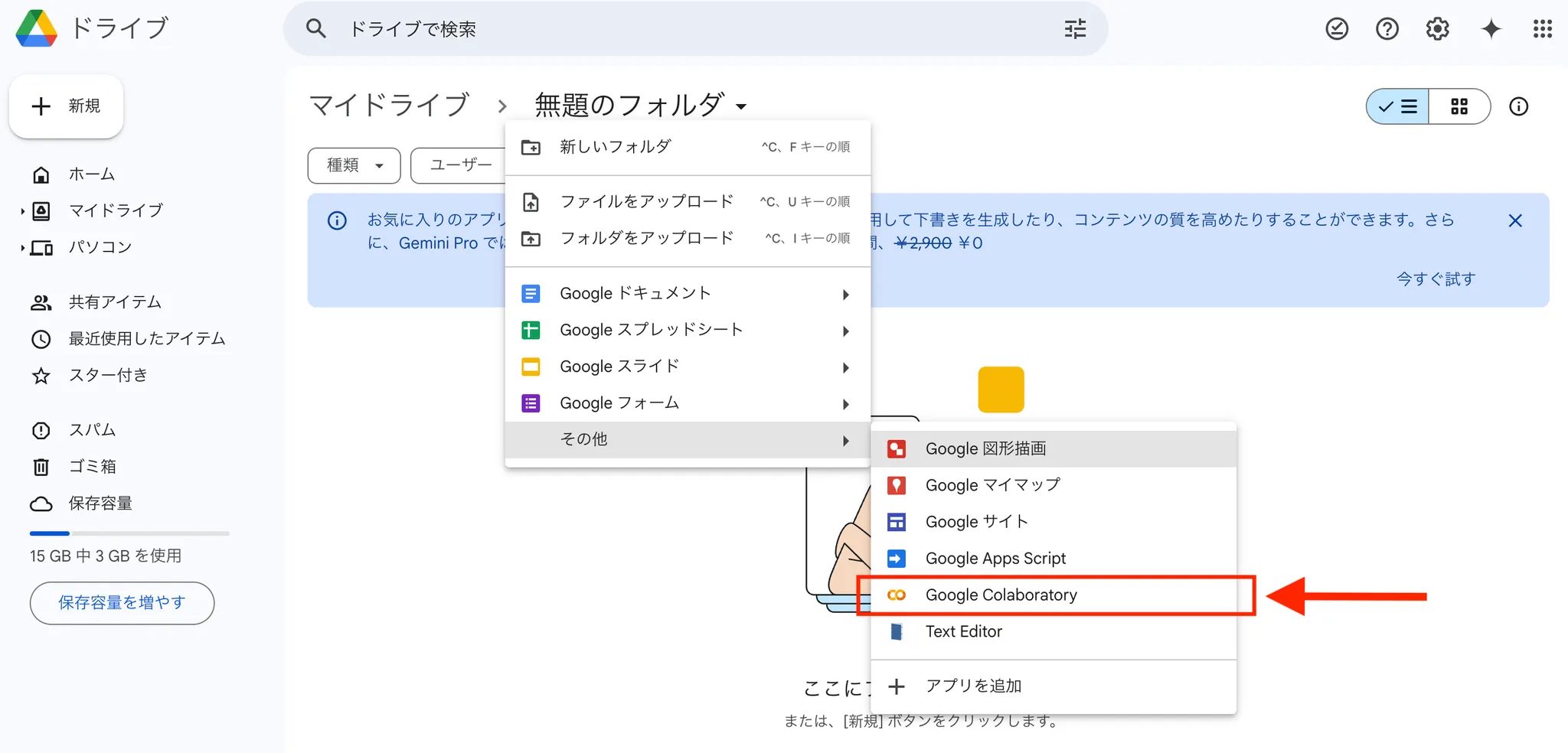
4.Colabの「ランタイム」というタブをクリック
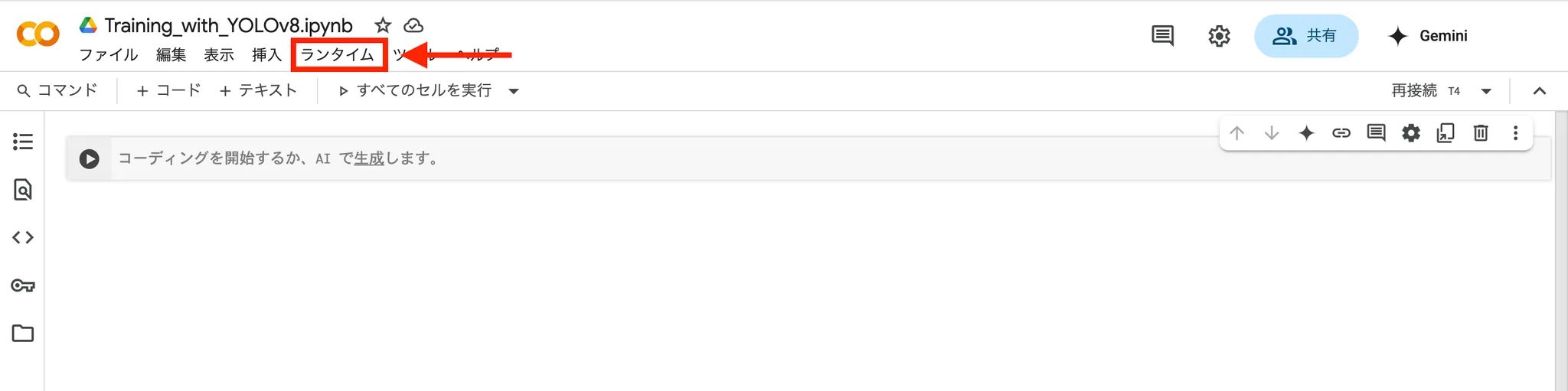
5.「ランタイムのタイプを変更」をクリック
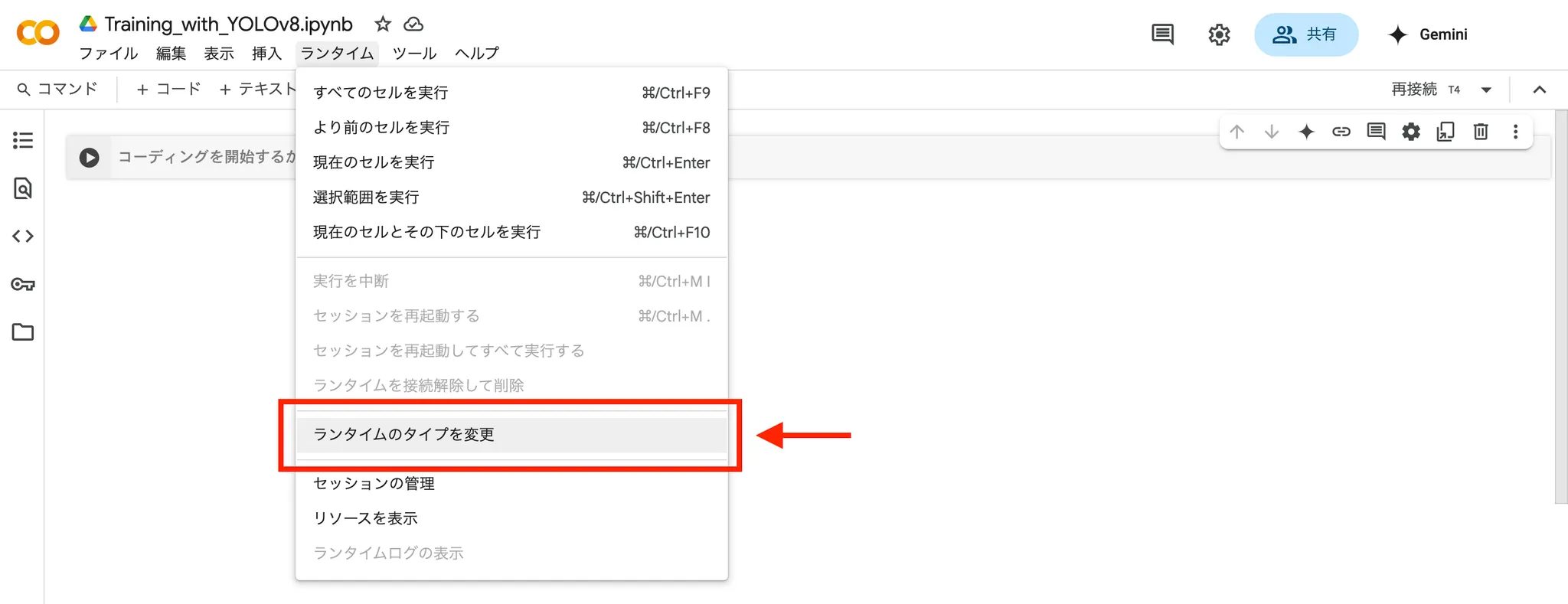
6.「T4 GPU」を選択し、保存する。
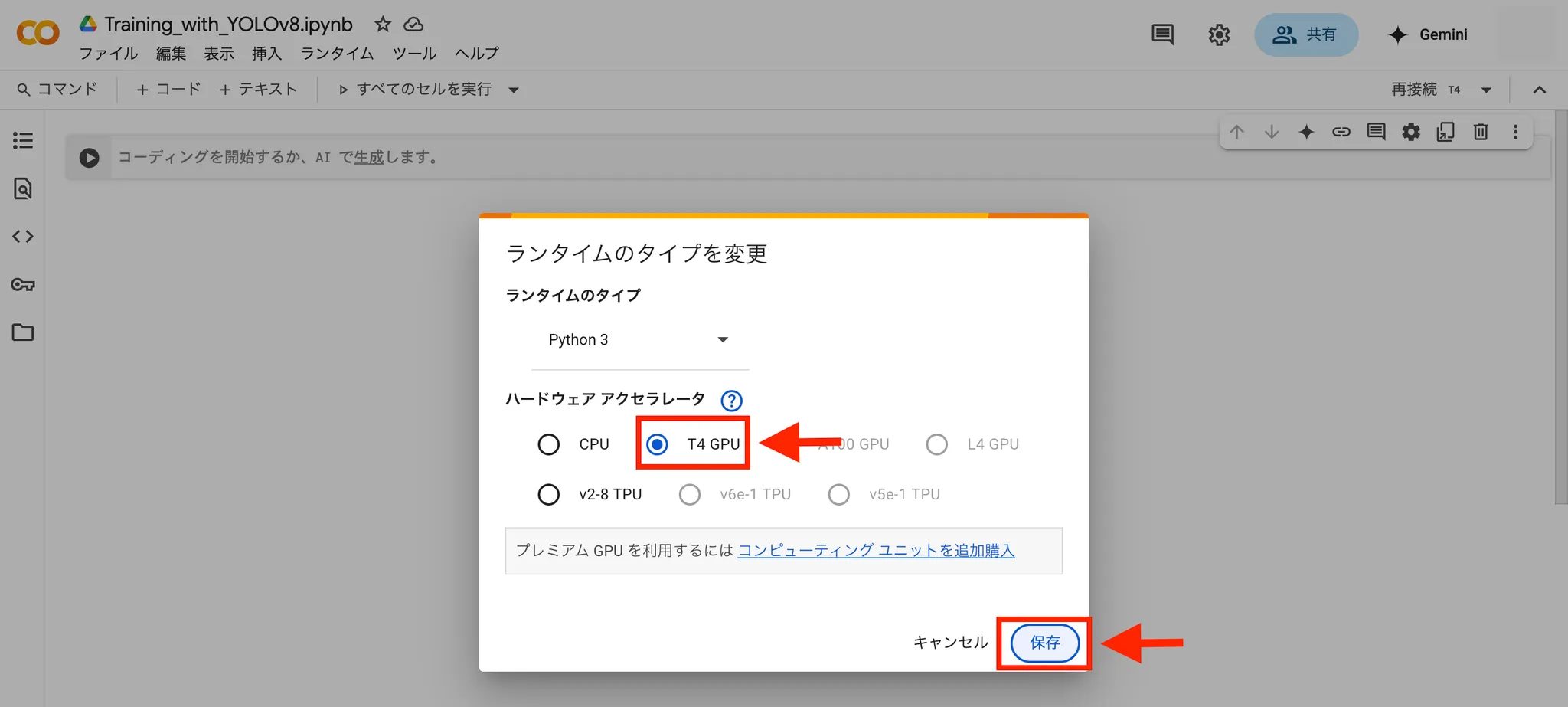
これでGPUを使って学習することができます。
7.Driveをマウントする。
Google DriveとColabを連携するために、Driveをマウントします。
以下のコードをセルで実行してください。
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
8.以下のコードをセルで実行し、作業ディレクトリを変更します。
|
1 |
%cd "作業ディレクトリへのパス" |
9.YOLOv8環境構築
YOLOv8を使った物体検出を行うには、まずUltralyticsが提供するライブラリをインストールする必要があります。以下のコマンドで、YOLOv8を含む関連パッケージをインストールします。
|
1 |
!pip install ultralytics |
インストールが完了したら、次にYOLOクラスをインポートして、モデルの学習や推論ができる準備をします。
|
1 |
from ultralytics import YOLO |
これで、YOLOv8を用いたモデルのロードや学習、推論が行える環境が整いました。
10.yamlファイルの作成
モデルにdatasetを入力するための設定ファイルを作成します。
以下のコードを実行してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
yaml_content = """\ # 訓練用画像、検証用画像のフォルダまでのパスをそれぞれ記述する # パスは step.8 「作業ディレクトリの変更」のパートと同様に取得することができる train: /content/drive/MyDrive/.../dataset/images/train val: /content/drive/MyDrive/.../dataset/images/train nc: 1 # クラスの数 names: [ 'dog' ] # クラスの名前のリスト """ # ファイルとして保存 with open("data.yaml", "w") as f: f.write(yaml_content) |
11.学習(training)
以下のコードを実行して、YOLOv8nという学習済みのモデルをファインチューニングします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 1. モデルのロード model = YOLO("yolov8n.pt") # Nanoモデルを事前学習済みのウェイトで読み込み # 2. 学習実行 results = model.train( ### Train settings ### data="data.yaml", # データ設定ファイルのパス epochs=100, # 総エポック数:100 imgsz=640, # 入力画像サイズ:640×640 にリサイズ batch=16, # バッチサイズ:16 device=0, # GPU0を使用。CPUなら"cpu"、複数GPUなら[0,1]なども可 # project="runs/detect/train", # 出力ディレクトリのパス # name="my_project", # プロジェクト内のサブフォルダ名 optimizer="SGD", # オプティマイザの選択 ### Augmentation Settings ### ) |
パラメータは他にもあるので公式ドキュメントを参照し、試行錯誤してみてください。
https://docs.ultralytics.com/modes/train/#train-settings
学習済みモデルはデフォルトで、/作業ディレクトリ/runs/detect/train/weights/best.pt として保存されます。
出力ディレクトリを変更したい場合は、step.11 のパラメータproject=”出力ディレクトリのパス” を変更しましょう。
変更せずに複数回学習を行うと自動で、train, train2, train3, … というように連番が付与されて学習結果が保存されます。step.11 のname パラメータを変更することでプロジェクトの名前を指定することができます。
12.推論(Inference or Predict)
それでは学習したモデルを用いた推論を行いましょう。
作業ディレクトリに推論を行いたい画像を配置してください。sourceパラメータに推論を行いたい画像のファイル名を指定してください。(例: test.jpeg)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 1. 学習済みモデルをロード # 'runs/detect/train//weights/best.pt' はデフォルトの学習出力先です。 model = YOLO('ここに学習済みモデルのパスを入力') # 2. 推論設定 # ・source: 画像パス ('image.jpg')、ディレクトリ ('/path/to/images/') # ・imgsz: 推論時の入力サイズ (学習時と同じ推奨) # ・conf: 信頼度閾値 (0.0~1.0) # ・iou: NMS(非最大抑制)のIoU閾値 # ・device: 'cpu' or '0','1'…(GPU デバイス番号) results = model.predict( source='test.jpeg', # 単一画像なら 'test.jpg'というようにファイル名のみ imgsz=640, conf=0.25, iou=0.45, device='0', save=True, # 推論結果の画像を保存(デフォルト: runs/detect/exp) save_txt=False, # バウンディングボックス情報をYOLOフォーマットでテキスト保存 ) |
下記の様な推論結果が、/runs/detect/predict/ に格納されていたら成功です。

https://docs.ultralytics.com/ja/usage/python/#predict
チャレンジ問題
1. 複数の物体を検出しましょう
例: 以下のように一つの画像に複数の物体が写っている場合の物体検出です。

2. 精度(mAP)を向上させましょう
あなたも、Avintonでこのような最先端技術を習得し活用してみませんか?
社員の成長を導きながら、AIやビッグデータなどの最先端技術をプロジェクトに活用していくことが私たちのビジョンです。Avintonの充実した技術研修でスキルアップを図り、あなたのキャリア目標を一緒に達成しませんか?

