Pandasとは
PandasはPythonで構造化データを解析する際に用いるライブラリです。 ここでいう構造化データとは行と列持ったデータでSQLデータベースやExcel等で管理されるものを指します。 その対をなす概念として非構造化データというものがありますが、それは画像や音声等の構造化データの形式に当てはまらないあらゆるデータを指します。 PandasはCSVやテキストファイル、Excel、SQLデータベース等のフォーマットのデータを読み書きすることができます。 構造化データの処理はデータの大きさによって時間がかかるので、パフォーマンスのため重要なコードはCythonまたはC言語で実装されています。
Pandasでできること
データの変形やピボット、欠損値処理、結合、その他のデータ処理を簡単に行うことができます。 また、時系列データに特化した関数も幅広く用意されており、日付範囲作成や周波数変換、移動窓を用いた統計値や線形回帰、シフト、遅延などが使えます。 また、簡単なデータの可視化も行うことができます。 他のNumpy、statsmodels、 matplotlib、sklearn等の Pythonライブラリとも相性が良くデータ操作、および解析、そして機械学習で広く用いられています。 全くPandasに触れたことのない方はまずPandasの公式チュートリアルを一通り写経することをお勧めします。
アクティビティ
※今回のアクティビティではanaconda上のJupyter Notebookを使用します。
1. データ読み込み
pandasのインポートがまだの方は、アクティビティを始める前に行ってください。
|
1 |
sudo pip3 install pandas |
今回使用するデータはボストンの住宅価格に関するデータです。 データはこちらからダウンロードしてください。 train_housingDownload
1. Jupyter Notebookの新しいノートブックを作成してください。
2. Pandasをインポートしてください。
3. ダウンロードしたファイルをPandas Dataframeとして変数に格納してください。
2. データ操作
2-1 下記のページを参考に最初の五行を表示しましょう。
pandas.DataFrame.head 【結果の表示画面】
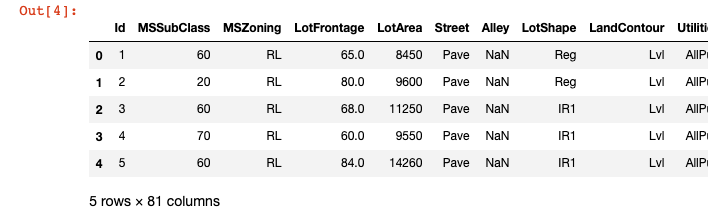
2-2 下記のページを参考に両データの次元数(行数, 列数)を確認しましょう。
pandas.DataFrame.shape 【結果の表示画面】
2-3 下記のページを参考に全ての列の名前を表示しましょう。
pandas.DataFrame.columns 【結果の表示画面】

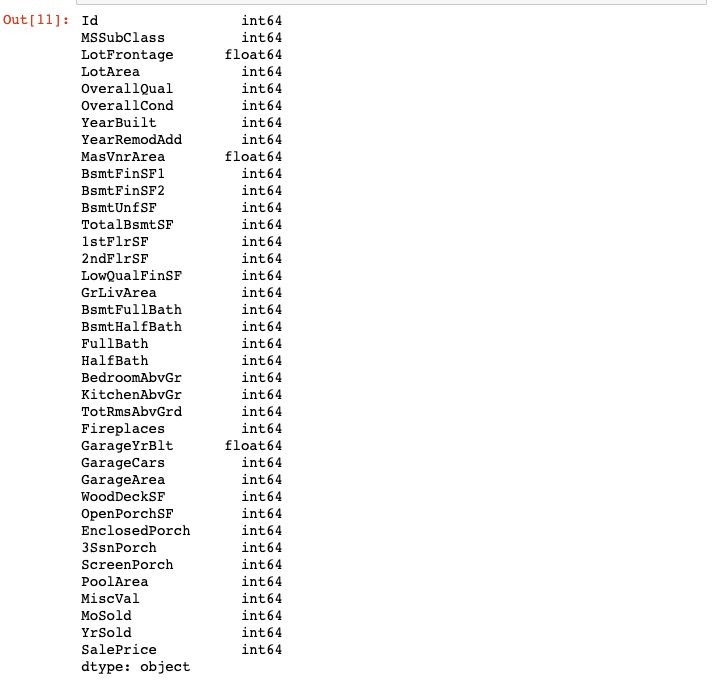
2-4 下記のページを参考に列ごとの基本情報を表示しましょう。
pandas.DataFrame.info 【結果の表示画面】

2-5 下記のページを参考に数値データのみが入ったデータフレームを新しく作成しましょう。
pandas.DataFrame.select_dtypes 【結果の表示画面】
2-6 下記のページを参考に、上で作成したデータフレームでSalesPriceと相関の高い上位10列を表示しましょう。
pandas.DataFrame.corr 【結果の表示画面】
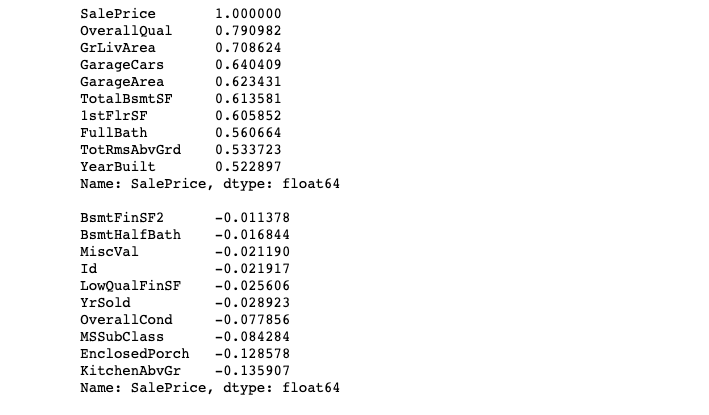
3. データの可視化
3-1 下記のページを参考に、SalesPrice列の分布の情報を表示しましょう。
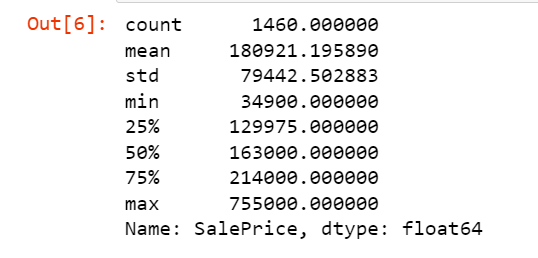
3-2 下記のページを参考にPandasの組み込み関数を使ってSalesPrice列のヒストグラムを表示しましょう。
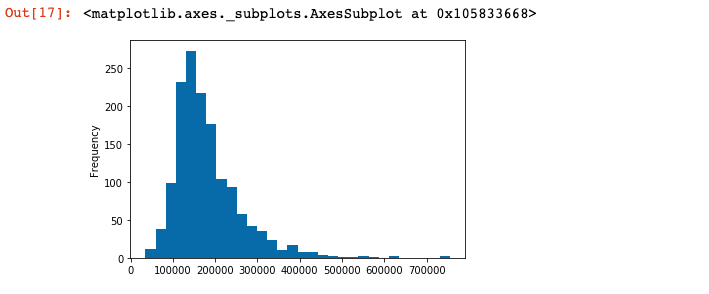
3-3 OverallQaulはSalesPriceと高い相関がありました。この列について分析しましょう。
3-3-1 OverallQualの固有値 (unique value) を表示しましょう。 ![]()
3-3-2 OverallQual列からピボットテーブルを作成し、SalesPriceとの関係を表示しましょう。 (集計には平均を使いましょう) 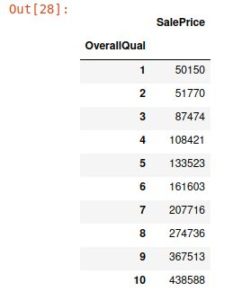
3-3-3 上のデータフレームを棒グラフとして表示しましょう。
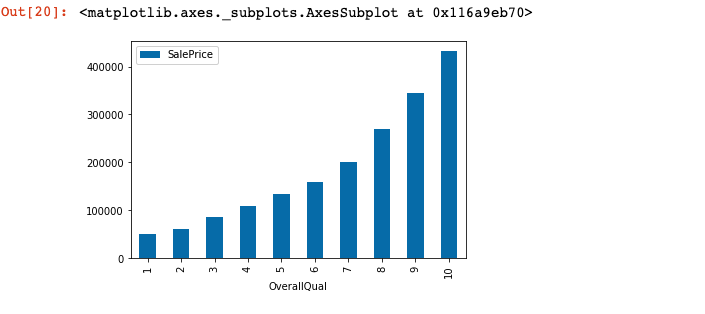
3-4 YearBuilt列についても分析しましょう。
3-4-1 YearBuilt列の範囲を表示しましょう。 ![]()
3-4-2 下記のページを参考にYearBuiltを10年ごとにビン分割(Binning)したYearBins列を生成しましょう。
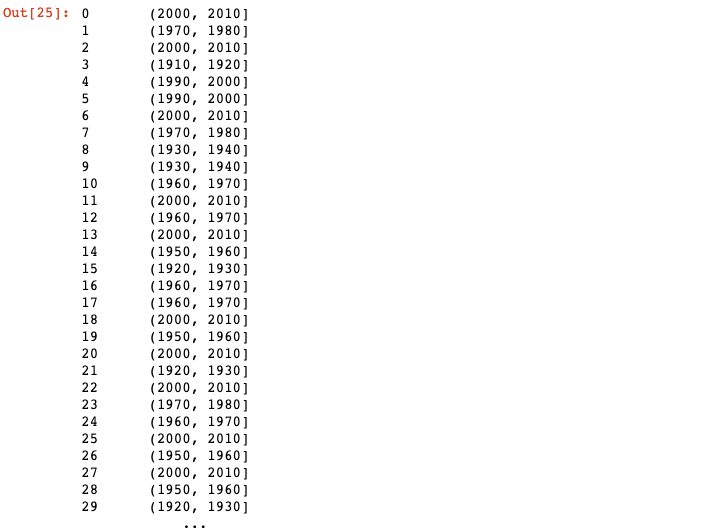
※ビン分割とは数値を大まかな範囲で分割することです。1995, 2003, 2019をそれぞれ10ごとにビン分割すると1990~1999, 2000~2009, 2010~2019となります。
3-5 下記のページを参考にSalesPriceとYearBins、OverallQualとの関係を箱ひげ図(Box Plot)で表示しましょう。
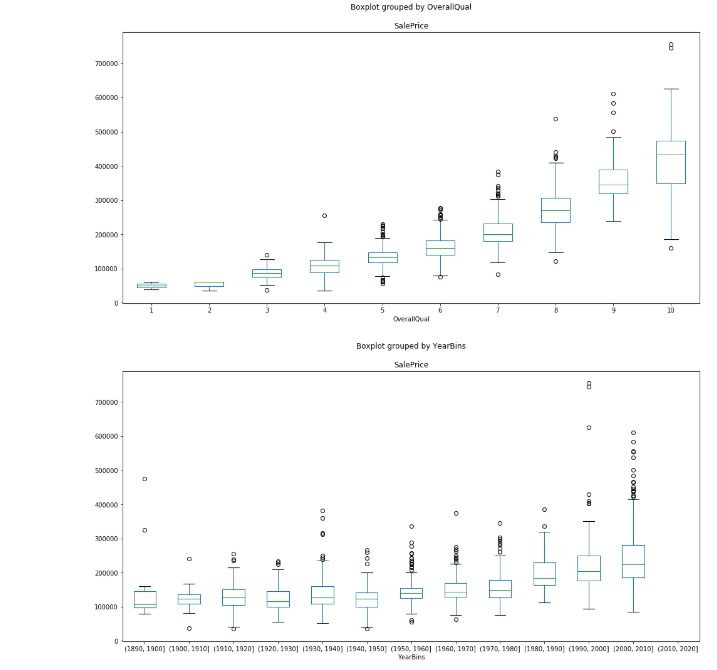
3-6 下記のページを参考にSalesPriceとGrLivArea、GarageCars、GarageArea、 TotalBsmtSFの関係を分布図(Scatter Plot)として表示しましょう。
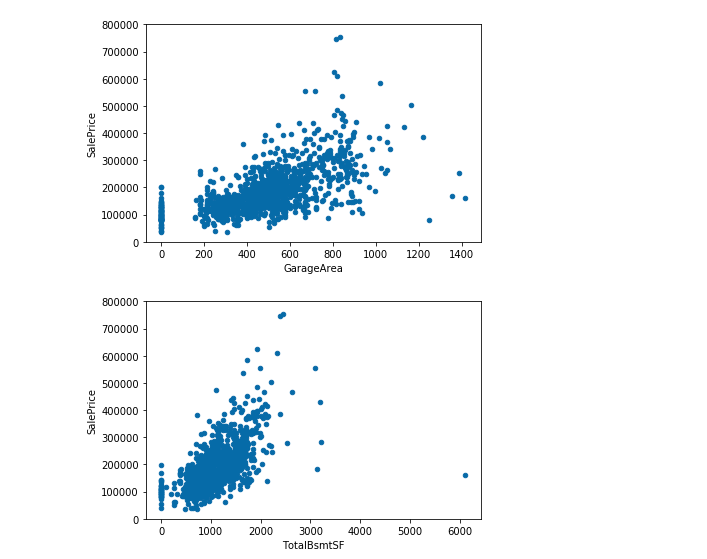
今回のアクティビティは以上です。 より高度なデータの可視化はmatplotlibやseabornを使うことで行うことができます。
あなたも、Avintonでこのような最先端技術を習得し活用してみませんか?
社員の成長を導きながら、AIやビッグデータなどの最先端技術をプロジェクトに活用していくことが私たちのビジョンです。Avintonの充実した技術研修でスキルアップを図り、あなたのキャリア目標を一緒に達成しませんか?

