PostgreSQL – インデックスを利用したパフォーマンス改善方法
データベースのパフォーマンス改善において、クエリの実行プランを最適化することは非常に重要です。
インデックスを活用することでデータの検索速度を大幅に向上させることができます。
本記事では、PostgreSQLのEXPLAINコマンドとANALYZEオプションを用いたクエリプランの確認方法や、インデックスを適用した際のパフォーマンス改善効果について詳しく解説します。
PostgreSQLのセットアップ
スキーマ、テーブルの作成
データベースにスキーマを設定し、必要なテーブルを作成することが最初のステップです。
ここでは、地理情報を管理するテーブルを例にします。
|
1 |
CREATE SCHEMA test; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE test.geographical_data( id serial, pref CHAR(1), city CHAR(1), latitude FLOAT, longitude FLOAT ); INSERT INTO test.geographical_data (pref, city, latitude, longitude) SELECT CHR(ASCII('A') + FLOOR(random() * 5)::int) AS pref, CHR(ASCII('a') + FLOOR(random() * 26)::int) AS city, ROUND(CAST(random() AS NUMERIC), 3) AS latitude, ROUND(CAST(random() AS NUMERIC), 3) AS longitude FROM generate_series(1, 10000000); |
以下のようなテーブルデータが作成されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
postgres=# SELECT * FROM test.geographical_data LIMIT 10; id | pref | city | latitude | longitude ----+------+------+----------+----------- 1 | E | r | 0.248 | 0.722 2 | D | p | 0.614 | 0.874 3 | B | d | 0.908 | 0.002 4 | E | f | 0.746 | 0.219 5 | D | b | 0.875 | 0.204 6 | D | x | 0.182 | 0.12 7 | D | h | 0.235 | 0.152 8 | A | z | 0.269 | 0.981 9 | D | b | 0.947 | 0.659 10 | E | z | 0.533 | 0.426 (10 rows) |
作成されるデータのサイズ: 約500MB
行数: 1000万行
クエリプランの確認: EXPLAIN ANALYZEの使い方
PostgreSQLでは、クエリの実行計画を確認するためにEXPLAINコマンドを使用します。
さらに、ANALYZEオプションを追加すると、実際の実行結果も表示されるため、どのようにクエリが処理されたかが具体的にわかります。
以下のクエリを実行することで、各ステップのコストや実行時間を表示できます。
|
1 2 3 4 5 6 7 |
EXPLAIN ANALYZE SELECT * FROM test.geographical_data WHERE pref = 'A' AND city = 'a'; |
インデックス
現状、WHERE句を満たすデータを検出するためにはgeographical_dataテーブル全体を1行ずつスキャンする必要があります。geographical_dataテーブルに多くの行があり、この問い合わせで返されるのが数行の場合、非効率です。
その様な場合、prefやcity列にインデックスを使用することで、クエリ実行時のパフォーマンスを向上させることができます。
インデックスの種類
|
1 |
CREATE INDEX index_name ON schema.table_name (column1, column2...); |
演習
- 各インデックスを使用した際の合計コストや実行時間の改善率を以下の表の様にまとめましょう。
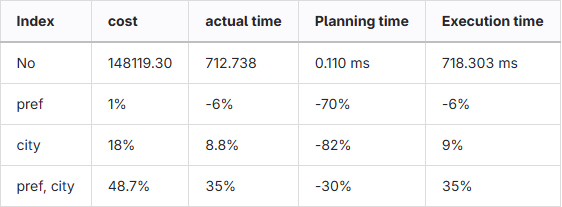
- クエリ実行時にインデックスが使用されているか使用されていないかを判断するにはどこを確認すればよいでしょうか。
- どの様な点を考慮してインデックスを使用すべきでしょうか。
- 以下のクエリをインデックスを用いて処理速度を改善しましょう。
|
1 2 3 4 5 6 7 8 9 10 |
EXPLAIN ANALYZE SELECT pref, city, latitude, longitude FROM test.geographical_data GROUP BY pref, city, latitude, longitude; |

