
画像:wikipedia
この記事では、ランダムフォレストという機械学習アルゴリズムをTitanicのデータセットに適用します。ここでは、分類問題においてのランダムフォレスト、決定木を扱います。
ランダムフォレストによる予測の結果、テストデータに対しての予測モデルの精度を確認し、その判断を下す際に重要視された特徴を確認します。
ランダムフォレストとは
ランダムフォレストとは、決定木をベースにした集団学習アルゴリズムです。
決定木では、木の深さに制限を設けないと、訓練データに対して過剰適合してしまいます。その欠点を補うために、データの特徴の中からランダムに着目して作成した決定木を複数用意します。それら1つ1つの出力を踏まえて多数決を行い、全体として1つの予測結果を出力します。
決定木とは
決定木とは、データの特徴に関するif-thenルールでデータを分けていき、データ分岐の終端でそのデータが何のクラスに属しているかを判断するアルゴリズムです。
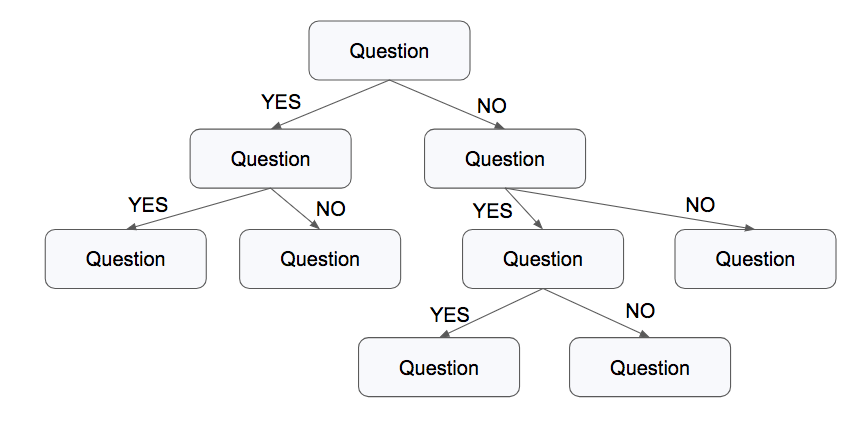
図のように、各データの持つ要素に関しての条件(またはQuestion)を各ノードに設定し、条件に従ってデータを分けていきます。決定木では深さの指定が無い場合には、データのクラスが完全に分けられるまで分岐を行います。深さを指定した木を途中で打ち切った場合、出力は各ノードにおいて最多数を占めるクラスとなります。
Titanicデータセットの用意
まずはTitanicのデータセットをkaggleからダウンロードします。
kaggle
- 1.kaggleのトップページからSign Inを押して、お持ちのfacebookアカウント等でログインするか、アカウントの作成します。
- 2.ログインが完了したら、ページ上部のcompetitionsに移動します。
- 3.ページ下部のTitanic: Machine Learning from Disasterを選択し、datasetのタブをクリックします。
- 4.そのページから、train.csvをダウンロードしてください。
プログラム
ここからは、実際にプログラムを実行していきます。
前提条件としては、Anacondaによってpythonと各種ライブラリがインストールされていることを前提とします。また、プログラムはJupyter Notebook上で動作するように書かれています。
Anacondaのインストール方法はこちらの機械学習を用いた画像分類体験アカデミーで解説しています。
こちらのJupyter Notebookをダウンロードしてプログラムを実行してください。
必要なライブラリのインポート
プログラムの実行に必要なライブラリをインポートします。
|
1 2 3 4 5 6 7 |
import numpy as np import matplotlib.pyplot as plt %matplotlib inline from sklearn.ensemble import RandomForestClassifier as RandomForest import pandas as ps from sklearn.model_selection import train_test_split |
データの読み込みと確認
csvファイルからdataを読み込みます。
読み込んだデータは、pandasのdataframe形式で扱うことができます。
|
1 2 |
data = ps.read_csv('train.csv') data |
各列のデータ形式と、各列の要素にNaNが含まれているかを確認します。
|
1 2 |
print(data.dtypes) print(data.isnull().any()) |
データの整形
性別を文字列から数値に変換します。
|
1 |
data['Gender'] = data['Sex'].map({"female": 0, "male": 1}).astype(int) |
年齢の欠損値を欠損していない年齢の中央値で補完します。
|
1 |
data["Age"] = data["Age"].fillna(data["Age"].median()) |
分析に使用しない列を削除します。
|
1 |
data = data.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1) |
データから乗船者のidと生存ラベルを取り除いたデータと、生存ラベルとに分けます。
|
1 2 |
X = data.drop(['Survived', 'PassengerId'], axis=1).values y = data['Survived'].values |
先ほど分離したデータを訓練データとテストデータとに分けます。
|
1 |
X_train, X_test, y_train, y_test = train_test_split(X, y) |
予測モデルの作成と評価
訓練データをもとに、ランダムフォレストによる予測モデルを作成します。
n_estimatorsでは、ランダムフォレストで作成する決定木の数を指定します。
|
1 |
model = RandomForest(n_estimators=100).fit(X_train, y_train) |
テストデータに対する予測の正解率を出力します。
船の乗客の情報X_testを入力として生存予測(0,1)を行い、その予測とy_testで与えられる正解を比較して、その結果の正解率(数値)が表示されるはずです。
|
1 |
model.score(X_test, y_test) |
ランダムフォレストの予測で用いられた各変数の重要度を出力します。
|
1 2 3 |
header = np.array(data.drop(['Survived', 'PassengerId'], axis=1).columns) print(header) print(model.feature_importances_) |
あなたも、Avintonでこのような最先端技術を習得し活用してみませんか?
社員の成長を導きながら、AIやビッグデータなどの最先端技術をプロジェクトに活用していくことが私たちのビジョンです。Avintonの充実した技術研修でスキルアップを図り、あなたのキャリア目標を一緒に達成しませんか?

